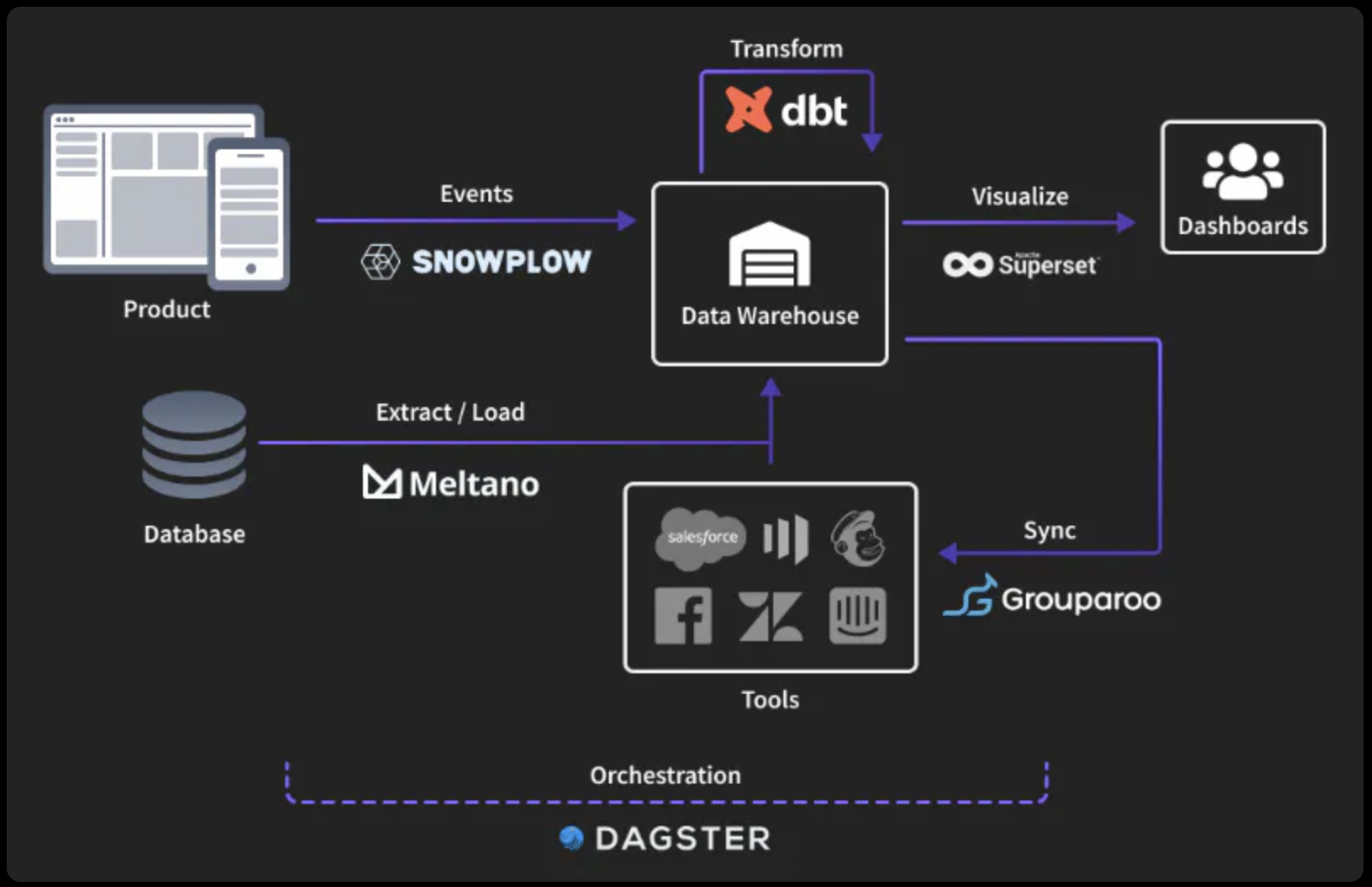
Back in May, I attended apply(), Tecton’s second annual virtual event for data and ML teams to discuss the practical data engineering challenges faced when building ML for the real world. There were talks on best practice development patterns, tools of choice, and emerging architectures to successfully build and manage production ML applications.
This long-form article dissects content from 14 sessions and lightning talks that I found most useful from attending apply(). These talks cover 3 major areas: industry trends, production use cases, and open-source libraries. Let’s dive in!