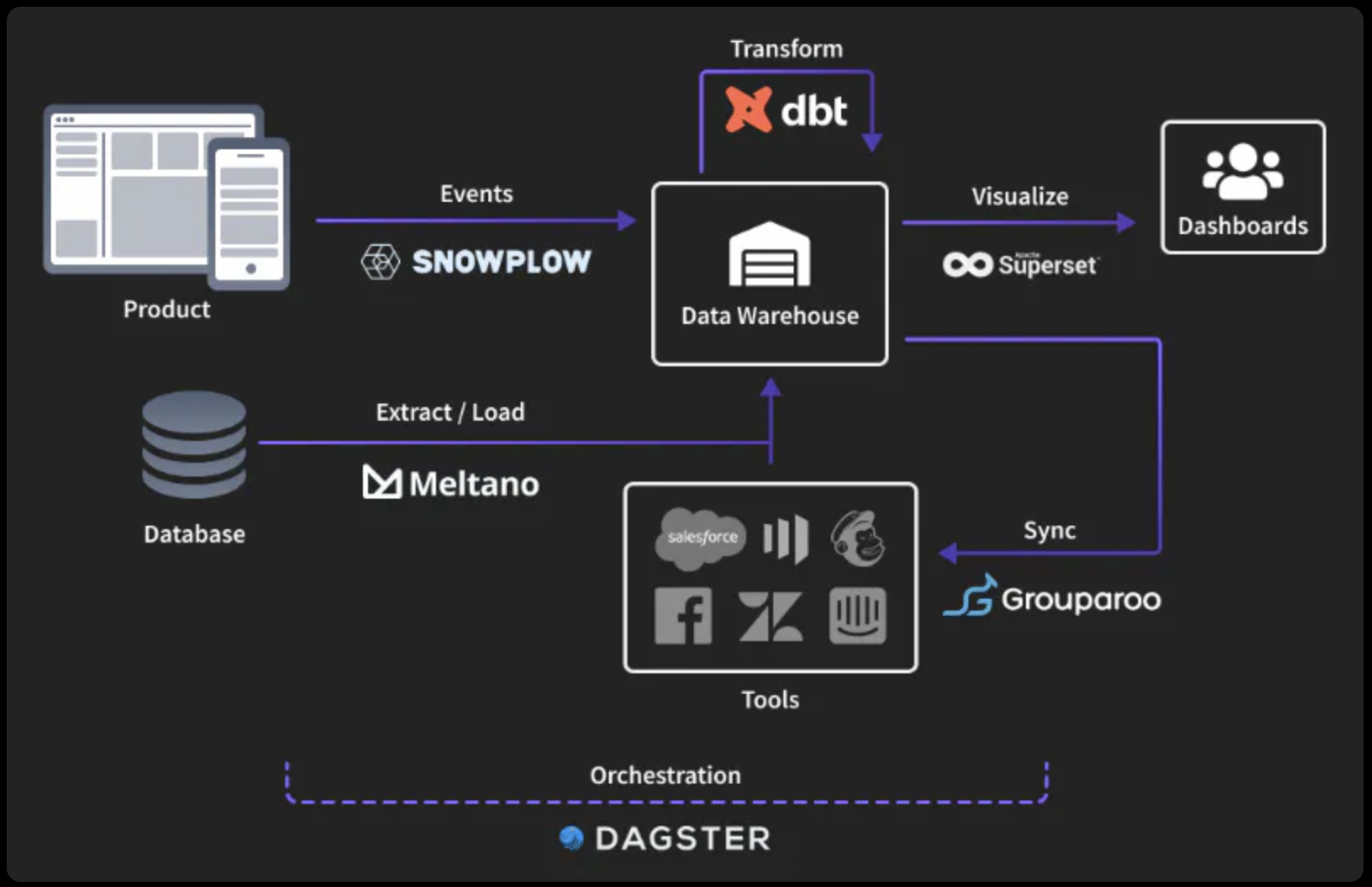
I attended the Open-Source Data Stack Conference in late September 2021, the first-ever conference dedicated to building a modern data stack using open-source data solutions. The emergence of the modern data stack has seen a rapid spike in the number of data tools an organization can use to drive better decision-making. Open-source software helps you control the end-to-end flow of customer data throughout your organization to guarantee data auditability, allow data governance, support consumer data privacy, and enable productive engineer workflows.
In this blog recap, I will dissect content from the conference’s session talks, each being a building block of the open-source data stack to demonstrate how teams can build a data stack that reflects their needs.
1 - Keynote
The modern data stack empowers data teams to work in unimaginable ways 5-10 years ago. From data engineers building efficient data pipelines, to analytics engineers adopting software engineering best practices, open-source makes it possible. James Densmore discussed how we got here and how open source fits technically and strategically on data teams today.
Here are the significant transitions that make the modern data stack (as we know it today) possible:
From row to columnar storage: About a decade ago, data warehouses were built most likely off of a row-storage OLTP database (such as MySQL or PostgreSQL). Row-storage databases are optimal for applications that read and write small sets of records, where all columns can fit in a record. However, tables in modern data warehouses are wide and deep. To address this, columnar-storage databases store data columns down, making it easier to distribute data across many nodes.
From on-prem to cloud warehouses: With the on-prem approach, you literally have to buy expensive appliances, set them up in your server room, maintain and scale them as business needs require. Cloud data warehouses (Snowflake, BigQuery, Redshift) have been game-changer. They make it affordable, accessible, and scalable to work with massive datasets.
From ETL to ELT: Cost-effective, columnar data warehouses sparked a revolution. Instead of extracting the data and transforming it before loading it to a more traditional database for performance and storage reasons, you now can skip that transformation step and put it at the end. Data teams have adapted to this evolution in system design and role specialty. Data engineers can own the extraction and the loading steps, while data analysts can take ownership of the transformation step more independently (also called “Analytics Engineers”). Analytics engineers start to work like software engineers as they adopt best practices in software engineering (version control, unit testing, separate development and production environments, etc.)
How does the open-source movement contribute to these transitions:
Open-source projects have been created to fill different gaps of the ELT (and now ELT+) paradigm. There are tools for data engineers to own the data ingestion and orchestration. There are tools for analytics engineers to transform data. There are operational analytics tools that empower data teams to get analytically derived data into operational systems such as CRMs, marketing workflows, and more.
As a result, you are no longer stuck in the single-enterprise-analytics mindset anymore. You can choose the open-source tools that work best for you at each point in your data pipelines. You get more flexibility, not locked into a single enterprise vendor.
In addition to that, the dreaded build-vs-buy question no longer poses a binary choice. Open source lets you integrate with the commercial products you choose. There is less risk of vendor alignment and lock-in.
Open-source also brings a great vibe to the data team culture, given its community nature. As a manager, you can think about the products that your engineers and analysts are passionate about (Slack communities, Meetups, etc.) Engineers feel more empowered and love to contribute to open-source projects (code, sponsorship, knowledge, etc.), so you should give them the opportunity!
Beyond ELT, James made a couple of remarks on trends worthy of attention:
Operational analytics (also known as “reverse ETL”) will continue to grow. This set of tools enables those who understand the analytical data to get it where it needs to go. The question is whether you’re putting the tools and governance in place to let it scale gracefully.
Data protection and privacy are no longer a “nice-to-have.” Open-source gives you a chance to “own” your data. Data governance, observability, and discovery just get started. It takes less time and capital than ever to get data into warehouses and lakes, transform it into models, and build dashboards. But how do we keep track of it all? How do people find it? How do we know when things go wrong?
Looking forward to the future, James emphasized the continued empowerment of those with domain knowledge of the data:
Analytics engineers gain more autonomy and independence.
Decentralized data organizations will become more common.
Data will be treated as a first-class citizen.
Given that vision, centralized data organizations will build platforms to enable analytics in their organizations. They will need full software engineering capabilities and focus on infrastructure/core “data” assets rather than domain-specific data modeling.
Conclusively, open-source will continue to drive innovation on the modern data stack. They have been successful in software development for a reason, so expect the same for analytics!
2 - Behavioral with Snowplow
To build a scalable open-source data stack, you need a powerful behavioral data engine to collect, enrich, and deliver behavioral event data to event streams, data warehouses, and data lakes. Alex Dean discussed his work at Snowplow and the possibilities of collecting behavioral data from all of your platforms and channels, then enriching and delivering it to the places you need.
Snowplow is a “batteries-included” behavioral data engine with tracking SDKs, a schema registry, enrichments, and data warehouse loaders. It’s essentially an open-source data processing pipeline. It loads behavioral data into data warehouses such as Snowflake, Redshift, BigQuery, and other destinations (S3, PostgreSQL, Kafka, etc.).
Furthermore, Snowplow also ships with dbt models, as they reduce time-to-value in building analytics and data products on top of behavioral data. Alex’s team has a dbt model for Snowplow behavioral data coming from websites and is working on a 2nd dbt model for Snowplow behavioral data coming from mobile apps.
Snowplow has been proudly open-source (under Apache 2.0 License) since launched in 2012. Their thesis is that organizations do not need a big data engineering team to use Snowplow, so the goal has always been making the software accessible to far more organizations. Besides that, Snowplow:
Supports data sovereignty: The behavioral data that flows through Snowplow is customers’ data (not Snowplow’s data).
Increases assurance: The users can audit and inspect all the data processing code.
Encourages ‘long-tail’ code contributions: There will be features that Snowplow users want but are not on the open-source roadmap. Snowplow’s architecture is modular and protocol-oriented, making it easy for contributors to add their own functionality.
Removes the risk of vendor lock-in: The premise of open-source software is that it will be around for a long time and continue to be permissively licensed.
There is also a commercial version of Snowplow, called Snowplow Insights (recently renamed as Snowplow Behavioral Data Platform), which provides a studio UI to help solve the organizational challenges of working with behavioral data at scale: How to decide what behavioral data to collect? How to structure that data? How to rapidly iterate behavioral data collection to meet evolving needs? How to build assurance in the accuracy and completeness of the data?
Snowplow Insights is sold as private SaaS - which Alex explained as a great model for open-source data infrastructure. Even though Snowplow Insights is a SaaS product, it runs inside a customer’s firewall. As a result:
The behavioral data never leaves customers’ AWS/GCP sub-account, so customers retain end-to-end data sovereignty.
Snowplow deploy, monitor, scale, and upgrade the underlying technology for customers.
Customers’ pipeline communicates with Snowlow’s centrally-hosted UI.
A typical organization can set up Snowplow by:
Defining schemas for specific events and specific entities.
Implementing tracking across web and mobile using Snowplow’s SDKs (thereby sending in the events and entities to Snowplow).
Configuring Snowplow enrichments and deploying dbt models.
Working with the Snowplow data in the data warehouse!
Snowplow behavioral data is rich: The data is a JSON payload sent in with reference to the associated schema. Schemas are namespaced to specific organizations and versioned. In addition to the event JSON, an array of associated entities can also be sent in. This data ends up validated and stored in the data warehouse in Snowplow-curated activity stream tables.
To get started with Snowplow, you can either:
Spin up the Open Source Quick Start, a set of Terraform modules to quickly set up a Snowplow pipeline on AWS. It supports Kinesis, S3, PostgreSQL, and Elasticsearch as destinations (with GCP and BigQuery coming soon). This is a good gateway into setting up a production Snowplow pipeline to load S3, Redshift, or Snowflake.
Try out the hosted free trial, Try Snowplow - which can easily be deployed in 5 minutes (with no AWS or GCP account). It is a good fit for data analysts with no experience in DevOps but who want to learn about the Snowplow data. This is a good gateway into the commercial product Snowplow Behavioral Data Platform.
3 - ELT with Meltano
Before you can dive into your data and uncover insights for your organization, you’ll face a challenge every data professional has encountered: data movement. Instead of writing custom code to run an extract and load job, wouldn’t it be better if there were other data professionals you could work with to solve this problem? Taylor Murphy showed how a community-driven, open-source approach is the best way to build the foundation and future of any data stack. His company Meltano focuses on extracting and loading data from various sources (databases, 3rd-party APIs, files) into the data warehouse.
The purpose of a data team is to help the organization make better decisions. So how should a data team function? Given the conference context, the data team builds data products and adds tools to the data stack to achieve that purpose.
The data product entails every piece of data that flows between people, systems, and processes; every analysis that the team produces; every tool with some analytic capability; and every spreadsheet that your team collaborates on. Simply put, if people are using it to make decisions, it’s part of the Data Product.
The data product is not a single tool or piece of software. It’s not just the things the data team procures or manages. It’s not the myriad other jobs that are being done.
Taylor frames data in the context of a product because good companies are product companies.
They have Product Managers, UX Researchers, Designers, Engineers, Technical Writers, etc. - all focused on solving customer problems. Good product teams have a vision and a strategy on where the product is going - driving revenue and good business outcomes.
Mapping that to the context of data teams, they should also have a clear vision and strategy, a deep understanding of their customers (coworkers), and possess various skills. All of these serve to iterate on the feature set of the data product and empower the company to make the best decisions possible.
A data leader guides the strategy and feature set of the data product.
As a company matures, the number of data sources increases, leading to stricter security requirements, a larger team, a tighter budget, and more mature processes.
In the worst-case scenario, your tool doesn’t support your weird APIs/databases/files and doesn’t work well with your stack/processes. You need to negotiate a new contract for additional data sources. Data security, privacy, and compliance become a concern around internal databases. The support team might not be helpful because the data team is on a lower tier.
In the best-case scenario, your tool supports your weird APIs/databases/files and works well with your stack/processes. You don’t need to negotiate a new contract for additional data sources. Data security, privacy, and compliance around internal databases are solved. The support community is helpful.
To avoid the worst-case scenario and achieve the best-case scenario, Taylor argued that it comes down to 3 key attributes: open-source, standards-based, and DataOps-first.
Why open-source? Open-source is all about the community. It is more accessible to the world. It is fixable, debuggable, and controllable.
Why standards-based? When there is a known specification you can build upon, you know the product will work. Shared standards enable a large community to come together to solve similar problems. They also enable reuse across the organization. Meltano uses Singer as the open-source standard for moving data and supports 300+ connectors in the Singer ecosystem.
Why DataOps? DataOps relies on principles like analytics-as-code, disposable environments, reproducibility, reuse, dynamism, and continuity. Adopting DataOps lets data teams collaborate confidently on data products.
These three attributes enable data teams to build a strong foundation to achieve the best-case scenario mentioned above.
4 - Orchestration with Dagster
You’ve got all the parts of your data stack set up -- now you have to make sure they work together. How do you ensure that upstream ingest jobs are completed in time for your warehouse transforms to run? How do you integrate external tools with the Python notebooks that build your ML models? What happens when something breaks, and how do you find out? Nick Schrock showed how an orchestrator lets you tame the dependencies between your tools and gives you visibility into your entire data platform.
The orchestrator manages the interoperability of all different technologies in a modern data stack. These technologies depend on each other in a variety of ways. For example, you can’t run dbt until data has made its way into Snowflake (or another data warehouse). Your Reverse ETL (such as Grouparoo) won’t have new information to load until dbt has updated its model.
The orchestrator is the single plane of glass where you can:
Define the dependencies between these technologies.
Learn how data flows from one point to another.
See operational information such as failures, logs, and history for any workflow you’re running.
While we have evolved with the data stack, Nick argued that data practitioners still have to deal with operational fragility (even with more efficient tooling). For many folks operating the modern data stack, the orchestrator is the missing critical component (as necessary as the cloud data warehouse, the transformation tool, the ingestion tool, etc.)
Furthermore, Python (or generally custom code) will always have a place in a modern data platform. There will be cases that require heavy transformation and filtering before data arrives in the data warehouse, or have a custom data source that doesn’t have a pre-built connector, or have custom scripts that maintain the platform itself. After data arrives in the data warehouse, you’ll again have reasons to return to custom Python code. For example, machine learning workflows overwhelmingly rely on Python to create features and train models. Therefore, data engineers should be able to wield and control Python transformations just as efficiently and conveniently as being able to use dbt for their SQL.
As a category, orchestration has a baseline utility level.
Your orchestrator should be able to efficiently sequence different steps in your workflow and schedule and execute the runs of those workflows. It should explicitly define dependencies between your tools. It is generally less confusing/error-prone than overlapping cron jobs.
Orchestration also offers visibility into the workflow execution. Generally, it provides a historical record of the executed runs and any relevant information about that execution. It should be able to alert you in various ways if something goes wrong.
Dagster, as an orchestration tool:
Has asset and data awareness: Dagster is intelligent enough to guide data from one step to another (while generating useful metadata along the way).
Embraces developer productivity mindset: An orchestrator should feel like a boost in productivity, not an obstacle that needs to be worked around to execute your code. Dagster is built with the developer workflow in mind, with (1) APIs that make it convenient to write tests that don’t need to touch production databases and (2) UI that makes it fun to debug pipelines.
Is a central system of record: Dagster is where you define your data platform.
Concluding his talk, Nick believed that the future of the modern data stack is more heterogeneous than the conventional wisdom in the modern data stack community says it is:
Off-the-shelf ingestion tools will not cover all use cases.
SQL will not eat all compute.
Data warehouses will not eat all data.
Needs will quickly evolve past a narrowly defined version of the modern data stack. As a result, the stack will expand or exist within the context of a broader platform. However, the principles that make the stack so effective will live on:
Managed and designed for the cloud era.
Defaulted to off-the-shelf if possible.
Adopting an engineering mindset for everything else.
5 - Transform with dbt
What happens after the data has been loaded into your data warehouse? You’ll need to transform it to meet your team’s needs. That’s where dbt comes in. dbt is a transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now anyone who knows SQL can build production-grade data pipelines. Julia Schottenstein talked about the workflows dbt enables and gave a short demo of how the platform works.
dbt Labs was founded to solve the workflow problem in analytics. The company created the tool dbt to help anyone on the data team model, test, and document datasets using just SQL. They have an open-core product strategy:
dbt Core powers the transformation, testing, and documentation.
dbt Cloud is a proprietary product that helps teams develop and deploy dbt models with confidence and ease.
The shift to cloud data warehouses has changed how transformation could be done. Data transformation used to be a lengthy and resource-intensive process because most transformations have to take place before data lands in the warehouse (legacy ETL system). Cloud warehousing has made storage and compute cheaper, allowing transformation to happen in place (modern ELT). This shift from ETL to ELT created the space for dbt to fundamentally change the analytics workflow. Data engineers virtually store all data in the cloud and let folks closer to business priorities decide how they want to model and shape the data for their needs.
There are two primary ways to perform data transformation today: traditional ETL providers that offer a GUI for messaging data and custom Python code and schedulers. While both methods have their advantages, they both share a common problem. They require highly-trained and hard-to-come-by individuals to manage the data transformation process, which is expensive and hard to scale and creates a workflow bottleneck. Those who want to express business logic do not have the tools to do transformations themselves. These analysts become reliant on a smaller specialized group to produce clean data tables for analytics purposes. Ultimately, the data workflow process becomes slower with many back-and-forth requests and the frustration of getting data in the right shape - leading teams to settle with less-than-ideal outcomes.
dbt solves this frustration and fixes the data workflow problem:
SQL is the language of every modern cloud warehouse and is known by every analyst/engineer alike. By creating a solution that leverages modular portable SQL, dbt makes transformations both faster and more accessible to more people on the data team.
With rigorous testing, version control, continuous integration, and automated documentation, dbt promotes speed and reliability.
While transformation is at the core of what dbt does, it is also a platform that lets you develop, test, document, and deploy your data models. dbt pushes all compute down to the data warehouse. As a result, security is ensured (data never leaves the warehouse), and data operations are faster (no added network latency).
dbt also invests heavily in metadata to (1) help data teams respond to data incidents, (2) understand provenance for datasets in their use cases, (3) address performance and quality improvements, and more. As the producers of these datasets, dbt is uniquely positioned to observe how business logic changes and how data changes. As a result, dbt can provide valuable insights for data consumers.
dbt’s development framework promotes four key outcomes:
Collaboration: dbt code is SQL-based and self-documenting. Everyone can work together.
Velocity: dbt focuses on analytics, not infrastructure. Teams can ship data products 3x faster.
Quality: dbt users can test and work from the same assumption to ensure alignment.
Governance: dbt standardizes processes and control access to simplify compliance.
dbt isn’t just software. It changes the way people work. With dbt at the center of your data stack, your teams will be more collaborative, work faster, and ship more reliable data products. Julia emphasized that the world needs more purple people - humans with a mix of a deep understanding of business context AND a breadth of technical expertise. Analytics engineers are purple people and a critical sherpa of guiding companies to the promised land, where data actually helps teams make better decisions for the business
6 - Analyze with Superset
Now that you have a modern data stack to handle storage and computation, it’s time to choose a business intelligence platform to enable your organization to create and socialize visual insights from your data. Max Beauchemin discussed his frustrations with proprietary BI platforms and what led him to help create Apache Superset.
Max made a case for open-source as the future of business intelligence in a blog post back in March. Essentially, he argued that legacy BI tools are too rigid, expensive, and hard to use. Open-source BI solutions are open, flexible, and customizable (with community-driven innovation/support, integration with modern data technologies) - thereby enabling organizations to avoid vendor lock-in and achieve faster time-to-value.
Max created Apache Superset while at Airbnb in 2014. It is the most popular open-source BI platform with a large and growing community of data professionals worldwide. Here are its powerful capabilities:
All-in-One Data Platform: Superset is a single platform for dynamic dashboarding, code-free expiration, and deeper analysis through a SQL IDE.
Integration with Modern Sources: Users can query any data source (cloud data warehouses, data lakes, and SQL engines).
Rich Visualizations and Dashboards: Superset has a wide variety of beautiful visualizations (including advanced geospatial renderings).
Extensibility and Scalability: Superset is cloud-native and leverages the power of your database at a petabyte-scale. Users can extend the platform with add-ons to meet their use case.
Max recently started a company called Preset, which offers a commercial solution (Preset Cloud) on top of Superset. Users can get all the features in the latest version of Superset while taking advantage of Preset’s fully managed cloud service (auto upgrades, database driver support, role-based access control, multi-workspace environment, admin API, in-product onboarding, etc.) You can get started today!
7 - Operationalize with Grouparoo
You have invested in your stack, and now the warehouse has the data and insights to drive your business. Brian Leonard shared how Grouparoo can put that data to work in the tools your company uses like Salesforce, Mailchimp, and Zendesk.
To enhance the customer experience for a business’s high-value customers, you need to be able to automatically and seamlessly connect your customer data platforms and your data warehouses. This is called Reverse ETL, which writes from the data warehouse to the operational tools that your business teams use. This practice increases their efficiency and effectiveness while using the right data from the warehouse source of truth.
Grouparoo is a powerful tool that enables users to:
Define user records and properties from the data source.
Create a group to note who is a high-value customer.
Map properties and groups to destinations such as Marketo, Zendesk, and Facebook.
Brian then took some time to discuss the three data engineering trends that emerged from the conference and how they apply to Grouparoo:
Own your data: This means controlling your own stack for agility, compliance, and better decision-making. Best practices include putting your warehouse at the center instead of external tools, iterating more quickly without data silos, and having a single source of truth to be shared among data consumers.
Data teams delivering data products: Teams are directly pushing to impact customers with their data solutions. They are now part of the core customer experience with internal and external integrations - embracing organizational collaboration around shared definitions. In Grouparoo, the data team provides the foundational knowledge.
Software engineering practices through DataOps: We evolve how we deliver these products through best practices from software development (iterative development, pipeline configuration as code, pull requests, tests, CI/CD, staging environments, etc.).
Brian has written an in-depth post explaining how Grouparoo supports the development workflow for Reverse ETL with an intuitive UI. Essentially, the UI enables users to introspect the source tables/columns and destination fields, verify credentials and preview data, work with sample profiles to iterate on nuances, and automatically write configuration files to check into source control.
That’s the end of this long recap. The modern data stack is the topic that I will focus a lot on in 2022. If you have experience using open-source tools to construct your modern data stack, please reach out to trade notes and tell me more at khanhle.1013@gmail.com! 🎆