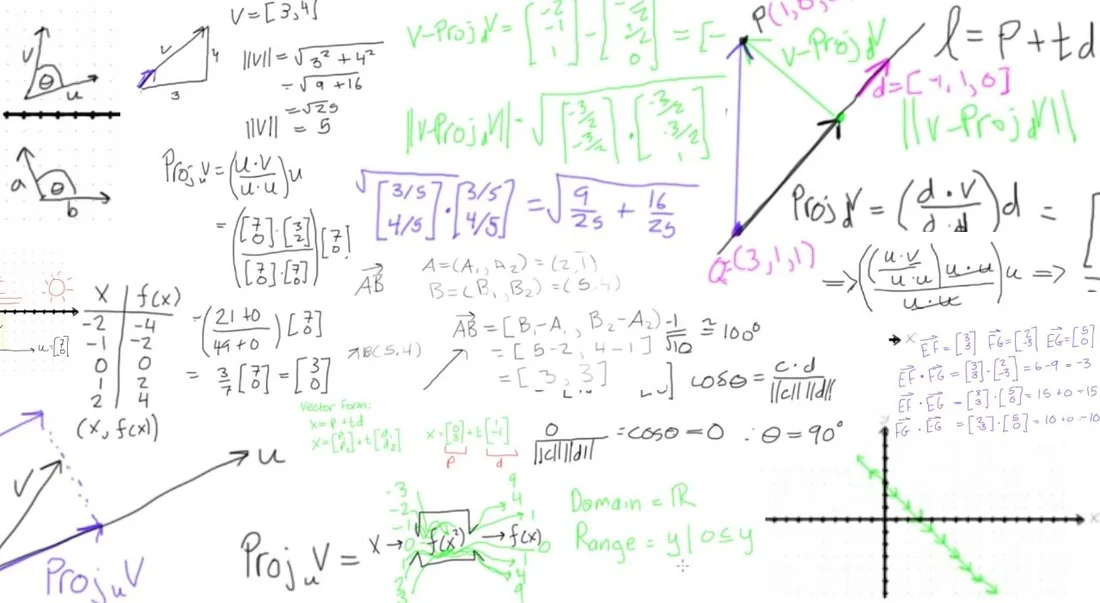
There have been significant advances in recent years in the areas of neuroscience, cognitive science, and physiology related to how humans process information. This semester, I’m taking a graduate course called Bio-Inspired Intelligent Systems. It provides broad exposure to the current research in several disciplines that relate to computer science, including computational neuroscience, cognitive science, biology, and evolutionary-inspired computational methods.