
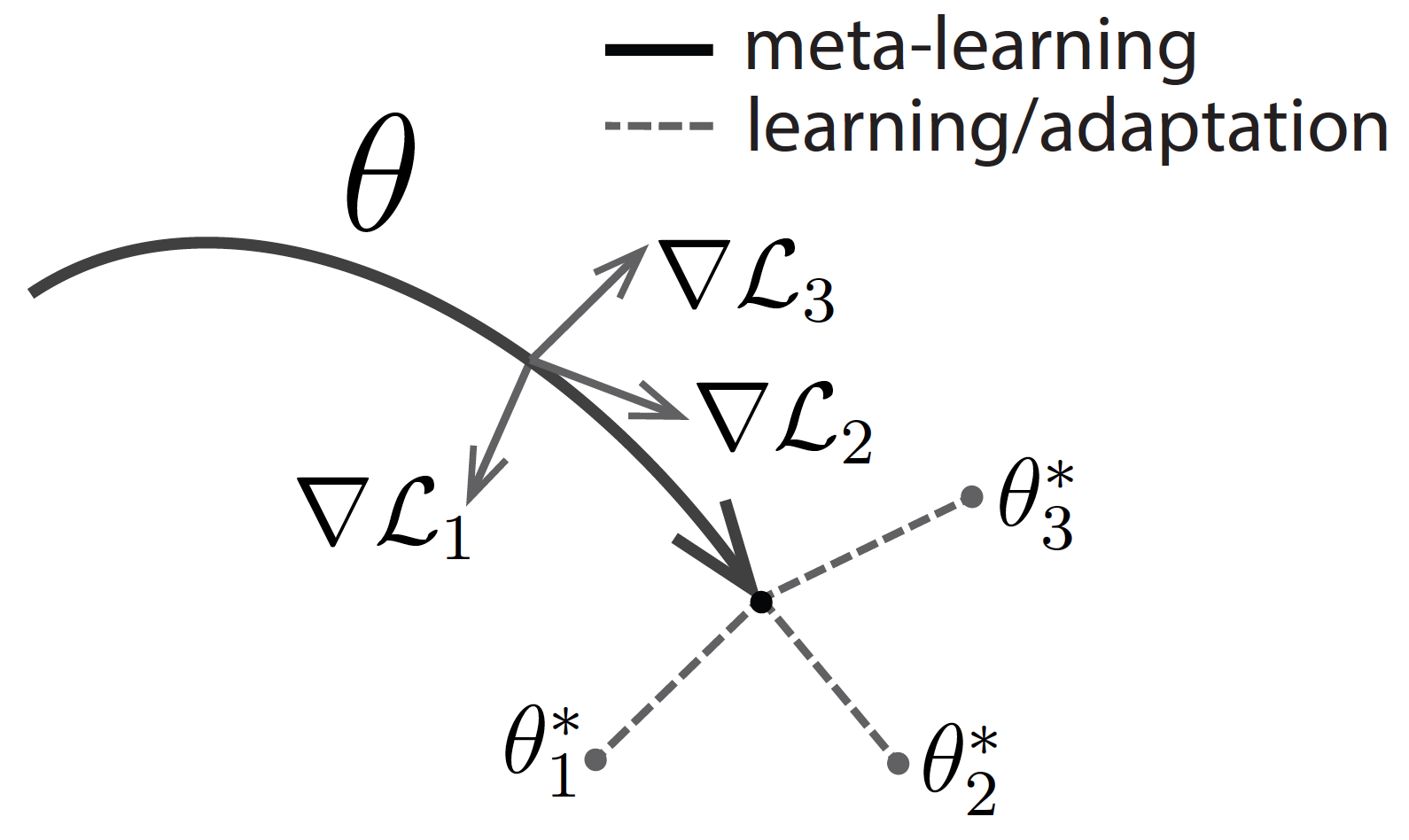
Meta-learning, also known as learning how to learn, has recently emerged as a potential learning paradigm that can learn information from one task and generalize that information to unseen tasks proficiently. During this quarantine time, I started watching lectures on Stanford’s CS 330 class on Deep Multi-Task and Meta Learning taught by the brilliant Chelsea Finn. As a courtesy of her lectures, this blog post attempts to answer these key questions:
Why do we need meta-learning?
How does the math of meta-learning work?
What are the different approaches to design a meta-learning algorithm?