
Based on a report from TechRepublic a few months ago, despite increased interest in and adoption of machine learning in the enterprise, 85% of machine learning projects ultimately fail to deliver on their intended promises to business. Failure can happen for many reasons, however, there are a few glaring dangers that will cause any AI project to crash and burn.
Machine learning is still research, therefore it is very challenging to aim for 100% success rate.
Many ML projects are technically infeasible or poorly scoped.
Many ML projects never make the leap into production, thus getting stuck at the prototype phase.
Many ML projects have unclear success criteria, because of a lack of understanding of the value proposition.
Many ML projects are poorly managed, because of a lack of interest from leadership.
I recently attended the Full-Stack Deep Learning Bootcamp in the UC Berkeley campus, which is a wonderful course that teaches full-stack production deep learning. One of the lectures delivered by Josh Tobin provided a solid introduction of how machine learning should be started and structured throughout its lifecycle on a technical level, but also on a business side level. I learned a ton on how to tackle a machine learning project, from requirements and planning to an assessment of your results in a professional setup. In this blog post, I would like to share the 5 steps that you can use to set up your projects up for success, as a courtesy of Josh’s lecture.
1 — Understand The Project Lifecycle
It’s important to understand what constitutes all of the activities in a machine learning project. Typically speaking, there are 4 major phases:

Josh Tobin at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
Phase 1 — Project Planning and Project Setup: At this phase, we want to decide the problem to work on, determine the requirements and goals, as well as figure out how to allocate resources properly.
Phase 2 — Data Collection and Labeling: At this phase, we want to collect training data (images, text, tabular, etc.) and potentially annotate them with ground truth, depending on the specific sources where they come from. We may find that it’s too hard to get the data, or it might be easier to label for a different task. If that’s the case, go back to phase 1.
Phase 3 — Model Training and Model Debugging: At this phase, we want to implement baseline models quickly, find and reproduce state-of-the-art methods for the problem domain, debug our implementation, and improve the model performance for specific tasks. We may realize that we need to collect more data or that data labeling is unreliable (thus go back to phase 2). Or we may realize that the task is too hard and there is a tradeoff between project requirements (thus go back to phase 1).
Phase 4 — Model Deploying and Model Testing: At this phase, we want to pilot the model in a constrained environment (i.e., in the lab), write tests to prevent regressions, and roll the model into production. We may see that the model doesn’t work well in the lab, so we want to keep improving the model’s accuracy (thus go back to phase 3). Or we may want to fix the mismatch between training data and production data by collecting more data and mining hard cases (thus go back to phase 2). Or we may find out that the metric picked doesn’t actually drive downstream user behavior and/or performance in the real world isn’t great. In such situations, we want to revisit the metrics and requirements of the projects (thus go back to phase 1).
2 — Know Which Projects Are Of High Priority
The next thing is to assess the feasibility and impact of your projects. The picture to your left shows a general framework for prioritizing projects. In other words, we want to build projects with high impact and high feasibility (aka, low cost).

Josh Tobin at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
High Impact — In the book “Prediction Machines,” the authors (Ajay Agrawal, Joshua Gans, and Avi Goldfarb) come up with a nice mental model on the economics of Artificial Intelligence: As AI reduces the cost of prediction and prediction is central for decision making, cheap prediction would be universal for problems across business domains. Therefore, you should look for projects where cheap predictions will have a huge business impact.
High Feasibility — In his popular blog post “Software 2.0,” Andrej Karpathy contrasts software 1.0 (traditional programs with explicit instructions) and software 2.0 (humans specify goals and the algorithm searches for a program that works). Software 2.0 programmers work with datasets, which get compiled via optimization — which works better, more general, and less computationally expensive. Therefore, you should look for complicated rule-based software where we can learn the rules instead of programming them.
In short, you need to remember 2 key points:
To find machine learning problems with high impact, you must look for complex parts of your pipeline and places where cheap prediction is valuable.
The cost of machine learning projects is primarily driven by data availability, and secondly by accuracy requirements.
3 — Figure Out Your Project Archetype
The next step is to understand the main categories of machine learning projects and their implications for project management. Generally speaking, there are 3 major project archetypes:
Projects that improve an existing process: improving route optimization in a ride-sharing service, building a customized churn prevention model, building a better video game AI…
Projects that augment a manual process: turning mockup designs into application UI, building a sentence auto-completion feature, helping a doctor to do his/her job more efficient…
Projects that automate a manual process: developing autonomous vehicles, automating customer service, automating website design…
Here are some key questions that you need to consider for each of these archetypes:
Projects that improve an existing process: Do your models truly improve performance? Does performance improvement generate business value? Do performance improvements lead to a data flywheel?
Projects that augment a manual process: How well does the system need to be so that the prediction can be useful? How can you collect enough data to make it that good?
Projects that automate a manual process: What is an acceptable failure rate for the system? How can you guarantee that it won’t exceed that failure rate? How inexpensively can you label data from the system?
Josh Tobin at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
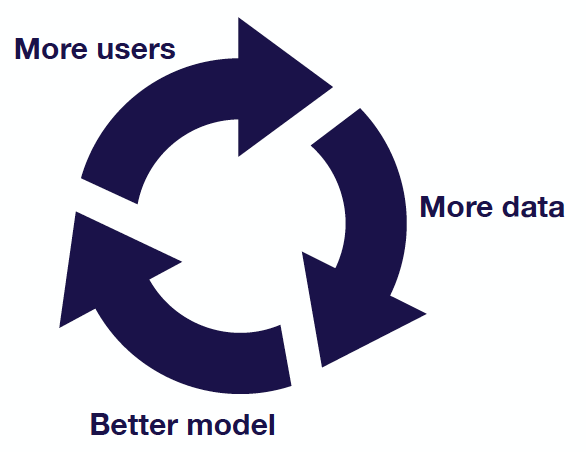
It’s also very important to understand the notion of data flywheels — in which more users lead to more data, more data lead to better models, and better models lead to more users (thus completing the flywheel). For each of the archetypes mentioned above, there is an appropriate strategy to automate this data flywheel:
For projects that improve an existing process, you would want to implement a data loop that allows you to improve on this specific task and future ones.
For projects that augment a manual process, you would want to have a really good product design, which can help reduce the need for accuracy. This article “Designing Collaborative AI” is a nice introduction to ways to start thinking about how to design systems where people and AI work together.
For projects that automate a manual process, you would want to add humans in the loop and limit the initial scope of the projects.
4 — Measure Project Metrics That Matter
For any machine learning projects, you would like to pick a single number (aka a metric) to optimize. Some of the most fundamental metrics in machine learning are accuracy, precision, and recall. Accuracy is the percentage of correct predictions that your model makes out of the total instances. Precision talks about how precise your model is out of the predicted positives (how many are actual positives). Recall calculates how many of the actual positives your model captures through labeling it as Positive (True Positive).

In most real-world scenarios, none of these needs are necessarily the one-and-only model metrics to optimize for. There are several creative ways that we can combine these metrics.
The first way is to do a simple average (or weighted average) of these metrics (for example, F1 score might be a good measure if you seek a balance between Precision and Recall).
The second way is to choose a metric as a threshold and evaluate at that threshold value (for example, evaluating the precision value when the recall value is higher than 0.5). The thresholding metrics are up to your domain judgment, but you would probably want to choose ones that are least sensitive to model choice and are closest to desirable values.
The third way is to use a more complex / domain-specific formula (for example, mean Average Precision over all classes). A solid process to go about this direction is to first start enumerating all the project requirements, then evaluate the current performance of your model, then compare the current performance to the requirements, and finally revisit the metric as your numbers improve.
The key takeaway here is that in most real-world projects, you usually care about a lot of metrics. Because machine learning systems work best when optimizing a single number, you need to pick a formula for combining different metrics of interest.
5 — Choose An Appropriate Project Baselines
It’s easy to overlook simple methods once you are aware of the existence of more powerful ones, but in machine learning like in most fields, it is always valuable to start with the basics. Fundamentally, a baseline is a model that is both simple to set up and has a reasonable chance of providing decent results. Experimenting with one is usually quick and low cost since implementations are widely available in popular packages.
Your choice of a simple baseline depends on the kind of data you are working with and the kind of task you are targeting. A linear regression makes sense if you are trying to predict house prices from various characteristics (predicting a value from a set of features), but not if you are trying to build a speech-to-text algorithm. In order to choose the best baseline, it is useful to think of what you are hoping to gain by using one.
So where should you look for baseline models?
You can look for external baselines such as business and engineering requirements, as well as published results from academic papers that tackle your problem domain.
You can also look for internal baselines using simple models (Linear/Logistic Regression, Gradient Boosted Trees, Simple Convolutional Architecture, and many more) and human performance.

Josh Tobin at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
The picture above gives more detail on how to create good human baselines. As you go from random people to a mixture of experts, the quality of your baselines would increase substantially, but it would also be much more challenging to collect the data (it’s hard to get connected with deep domain experts). Broadly speaking, the higher the quality of your baselines are, the easier it is to label more data. More specialized domains require more skilled labelers, so you should find cases where the model performs worse and concentrate the data collection effort there.
Conclusion
Being a new and evolving field, executing machine learning projects successfully is full of known and unknown challenges. If you skipped to the end, here are the final few take-homes:
Machine learning projects are iterative, so a good practice is to deploy something fast to begin the project lifecycle.
Choose projects that are high impact with a low cost of wrong predictions.
The secret sauce to making projects work well is to build automated data flywheels.
In the real world, you care about many things, but you should always have just one metric to work on.
Good baselines help you invest your effort the right way.
Hopefully, this post has presented helpful information for you to execute machine learning projects successfully. In the upcoming blog posts, I will share more lessons that I learned from attending the Full-Stack Deep Learning Bootcamp, so stay tuned!