
Introduction
In the past couple of years, we have seen a big change in the recommendation domain which shifted from traditional matrix factorization algorithms (c.f. Netflix Prize in 2009) to state-of-the-art deep learning-based methods. Currently, I am doing an internship for a startup that does video recommendation, and I can see clearly the main reasons behind such movement:
The signals coming from users (such as views) are not independently distributed observations but can be represented as sequences of actions. Understanding and modeling efficiently these sequences using recurrent neural networks (RNN) was key to improving the accuracy of a video recommender system.
Videos are often characterized by features (category of the video, description tags) which can be used to derive similarities between videos. Moreover, the context of the watch (device, country, …) is crucial in order to tailor the recommendation. Using them as features in a deep learning model has enabled faster convergence but also helped in the cold-start regime when no user signal is available for a given video.
Feedback (watches) can only be observed on a given video when the video has been shown to the users (bandit feedback). As a consequence, I do not know what would have happened if I had selected other videos for a given user (counterfactual reasoning). Learning in this type of setting requires special paradigms such as off-policy learning or counterfactual learning which have been used a lot in reinforcement learning for example. Recently, several works have been studying “deep learning” based models in these settings.
In this post and those to follow, I will be walking through the creation and training of recommendation systems, as I am currently working on this topic for my Master Thesis. In Part 1, I provided a high-level overview of recommendation systems, how they are built, and how they can be used to improve businesses across industries. In Part 2, I provided a nice review of the ongoing research initiatives with regard to the strengths and application scenarios of these models. Part 3 will address the limitations of using deep learning-based recommendation models by proposing a couple of research directions that might be relevant for the recommendation system scholar community.
Drawbacks
What are the drawbacks of using deep neural networks for a recommendation?
Based on my research, there are 3 major issues:
A common objection of deep learning is that the hidden weights and activations are hard to interpret. Deep learning is well-known to behave like black boxes, and providing explainable predictions seem to be a really challenging task.
Deep learning also requires a lot of data to fully support its rich parameterization. As compared with other domains like vision and language, it is easy to gather a significant amount of data within the context of recommendation systems research.
Deep learning needs extensive hyper-parameter tuning, which is a common problem for machine learning in general.
In order to tackle some of these problems, there have been a variety of research initiatives coming recently, and in this post, I will present 6 of them.
1 — Evaluation Methods
After reading an extensive amount of literature on recent publications presented at RecSys conferences, I noted that the choice of baseline models and evaluation datasets are quite arbitrary and up to the authors. The big issue with this is the obvious inconsistency in the reporting of scores, which makes the relative benchmark of new models extremely challenging.
Why is there no MNIST or ImageNet equivalencies for recommendation systems? The most commonly used dataset seems to be MovieLens; however, even in such cases, the train and test splits are also arbitrary. Furthermore, there is no control over the difficulty of test samples in recommendation system results (randomly, chronologically, etc.) Without a proper standard to design test sets, it would be challenging to estimate and measure progress in the field.
2 — Scalability For Large-Scale Settings
Scalability is critical to the usefulness of recommendation systems in industry settings. To that end, recommendation models can definitely be more efficient by exploring these following problems:
Incremental learning for non-stationary and streaming data (large volume of incoming users and items)
Computational efficiency for high-dimensional tensors and multimedia data sources
Balancing the complexity and scalability as the model’s parameters increase exponentially

A promising research area is to use compression techniques to compact the embedding space of high-dimensional input data, which can reduce the computation time during model learning. Another promising approach is to distill knowledge to learn compact models for inference in recommendation systems. The key concept is to train a small student model that absorbs knowledge from a large teacher model.
3 — Multi-Task Learning
Multi-task learning is an approach in which multiple learning tasks are solved at the same time while exploiting commonalities and differences across tasks. It has been used successfully in many computer vision and natural language processing tasks. A couple of recent works have also applied this technique to the recommendation system:
Ask The GRU: Multi-Task Learning for Deep Text Recommendations presents a method leveraging deep recurrent neural networks to encode the text sequence into a latent vector, specifically gated recurrent units (GRUs) trained end-to-end on the collaborative filtering task. For the task of scientific paper recommendation, this yields models with significantly higher accuracy.
Neural Survival Recommender presents a model based on Long-Short Term Memory to estimate when a user will return to a site and what their future listening behavior will be. In doing so, it aims to solve the problem of Just-In-Time recommendation, that is, to recommend the right items at the right time. It uses tools from survival analysis for return time prediction and exponential families for future activity analysis.
Neural Rating Regression with Abstractive Tips Generation for Recommendation proposes a deep learning-based framework named NRT which can simultaneously predict precise ratings and generate abstractive tips with good linguistic quality simulating user experience and feelings for E-Commerce sites. For abstractive tips generation, gated recurrent neural networks are employed to “translate” user and item latent representations into a concise sentence.
Expanded autoencoder recommendation framework and its application in movie recommendation employ stacked auto-encoders to extract the feature of input then reconstitution the input to do the recommendation. Then the side information of items and users is blended in the framework and the Huber function based regularization is used to improve the recommendation performance.
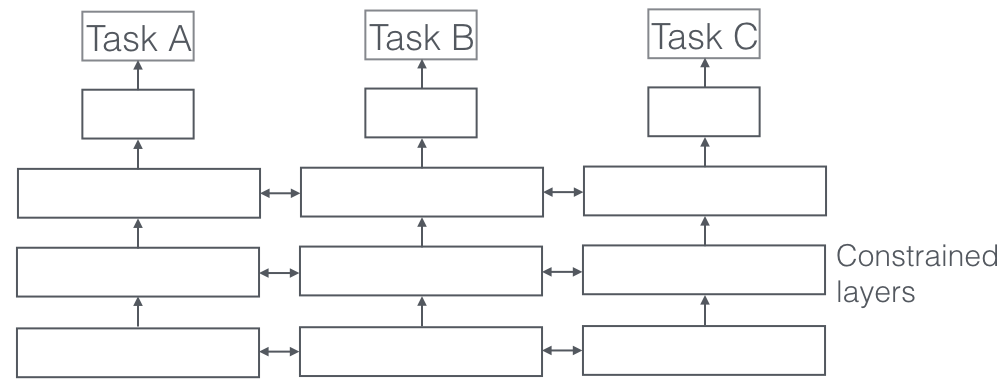
There are many advantages to using deep neural networks based on multi-task learning. It helps prevent overfitting by generalizing the shared hidden representations. It provides interpretable outputs for explaining the recommendation. It implicitly augments the data and thus alleviates the sparsity problem. Finally, we can deploy multi-task learning for cross-domain recommendations with each specific task generating recommendations for each domain (seen in the section below).
4 — Domain Adaptation
The single-domain recommendation system only focuses on one domain and ignores the user interests in other domains, which greatly exacerbates the sparsity and cold start problems. A tangible solution for these problems is to apply domain adaptation techniques, in which a model is assisted with the knowledge learned from source domains. A very popular and well-studied topic in this scenario is transfer learning, which can improve learning tasks in one domain by using knowledge transferred from other domains. Several existing works indicate the efficacy of deep learning in catching the generalizations and differences across different domains and generating better recommendations on cross-domain platforms.
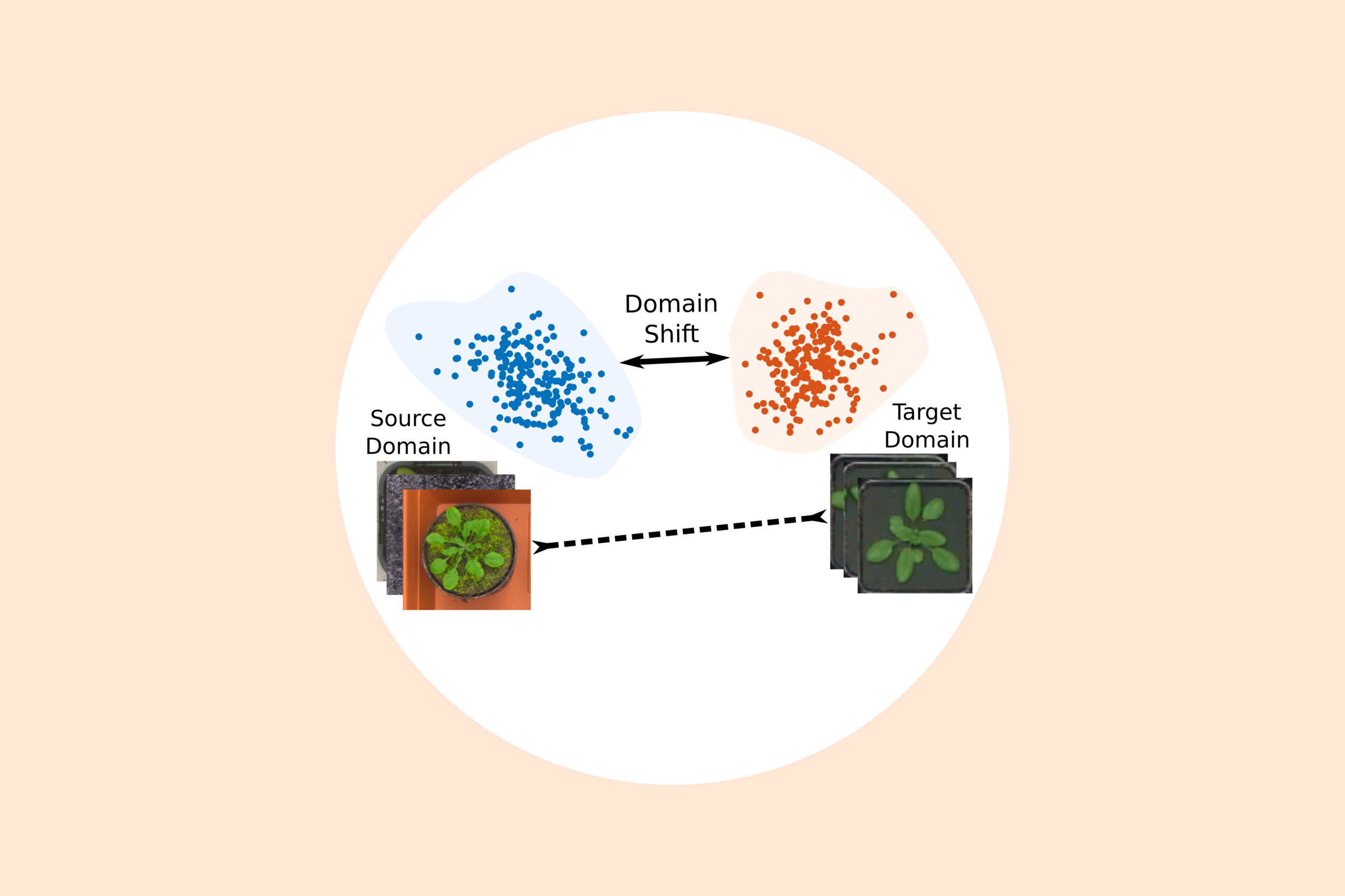
In “A multi-view deep learning approach for cross-domain user modeling in recommendation systems,” Microsoft Researchers propose a content-based recommendation system to address both the recommendation quality and the system scalability. They use a Deep Learning approach to map users and items to a latent space where the similarity between users and their preferred items is maximized, using a rich feature set to represent users, according to their web browsing history and search queries. They also show how to make this rich-feature based user representation scalable by reducing the dimension of the inputs and the amount of training data. The combination of different domains into a single model for learning helps improve the recommendation quality across all the domains, as well as having a more compact and semantically richer user latent feature vector.
In “A Content-Boosted Collaborative Filtering Neural Network for Cross-Domain Recommender Systems,” Microsoft Researchers propose a cross-domain recommendation system named CCCFNet which can combine collaborative filtering and content-based filtering in a unified framework, thus overcoming the data sparsity problem.
In my opinion, this is a promising research direction but is still largely under-explored for recommendation system research in general.
5 — Explainability and Interpretability
A common argument against deep learning is that the neural networks are highly non-interpretable. Thus, making explainable recommendations based on deep neural networks seem to be very challenging. There are mainly 2 ways that explainable deep learning is important.
The first is to make explainable predictions to users and allow them to understand the factors behind the network’s recommendations. Interpretable convolutional neural networks with dual local and global attention for review rating prediction proposes to model user preferences and item properties using convolutional neural networks (CNNs) with dual local and global attention, motivated by the superiority of CNNs to extract complex features. By using aggregated review texts from a user and aggregated review text for an item, their model can learn the unique features (embedding) of each user and each item. These features are then used to predict ratings.
The second is to understand more about the model by probing weights and activations. Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking proposes a model called Latent Relational Metric Learning which can learn latent relations that describe each user-item interaction. This helps to alleviate the potential geometric inflexibility of existing metric learning approaches. This enables not only better performance but also a greater extent of modeling capability, allowing their model to scale to a larger number of interactions.

Recently, attentional models have contributed much to ease the non-interpretable concerns of neural models. For instance, Attentional Factorization Machines learn the importance of each feature interaction from data via a neural attention network. The attention weights not only give insights about the inner workings of the model but are also able to provide explainable results to users. Generally speaking, attentional models can both enhance performance but provide neat explainability, which further motivates its usage on the deep learning-based recommendation system.
Noticeably, a model’s explainability and interpretability strongly rely on the application domain and usage of content information. Therefore, a promising research direction would be to design better attentional mechanisms, for example — conversational or generative explanations.
6 — Joint Learning Framework
Making accurate recommendations requires a deep understanding of item characteristics and the user’s actual demands and preferences. For example, context information can tailor services and products according to the user’s circumstances and surroundings, which helps mitigate the cold-start problem. Implicit feedback can indicate users’ implicit intention and complement the explicit feedback (which is a resource-demanding task). Such implicit feedback can be gathered from social media and the physical world, and deep learning can process these data sources while bringing more opportunities to recommend diverse items with unstructured data such as textual, visual, audio, and video features.
Furthermore, deep learning can help greatly to automate feature engineering, which currently requires manual intervention in the recommendation research community. There is also an added advantage of representation learning from free texts, images, or data in the wild without having to design intricate feature engineering pipelines.

A recent framework called Joint Representation Learning is capable of learning multi-modal representations of users and items. In this framework, each type of information source (review text, product image, numerical rating, etc) is adopted to learn the corresponding user and item representations based on available (deep) representation learning architectures. Representations from different sources are integrated with an extra layer to obtain the joint representations for users and items. In the end, both the per-source and the joint representations are trained as a whole using pair-wise learning to rank for the top-N recommendation. By representing users and items into embeddings offline, and using a simple vector multiplication for ranking score calculation online, JRL also has the advantage of fast online prediction compared with other deep learning approaches to a recommendation that learn a complex prediction network for online calculation. Therefore, another promising research direction is to design better inductive biases in an end-to-end pipeline, which can reason over different modalities data for better recommendation performance.
Conclusion
Deep learning has become more and more popular throughout all subfields of computer science, such as natural language processing, image and video processing, computer vision, and data mining, which is a remarkable phenomenon since there has not been such a common approach to be used in solving different kinds of computing problems before. With such an aspect of deep learning techniques, they are not only highly capable of remedying complex problems in many fields, but they also form a shared vocabulary and common ground for these research fields. Deep learning methods even help these subfields to collaborate with each other where it was a bit problematical in the past due to the diversity and complexity of utilized techniques.
Although the application of deep learning into the recommendation systems field promises significant and encouraging results, challenges such as explainability and scalability are still open for improvements and warrant future work. Personally, I am heavily interested in the domain adaptation techniques being used to recommend items, and would like to see that ImageNet moment for RecSys. Stay tuned for future blog posts of this series that go in-depth on the nitty-gritty details of how these models work.