
This semester, I’m taking a graduate course called Introduction to Big Data. It provides a broad introduction to the exploration and management of large datasets being generated and used in the modern world. In an effort to open-source this knowledge to the wider data science community, I will recap the materials I will learn from the class in Medium. Having a solid understanding of the basic concepts, policies, and mechanisms for big data exploration and data mining is crucial if you want to build end-to-end data science projects.
If you haven’t read my previous 3 posts about relational database, data querying, and data normalization, please do so. Here’s the roadmap for this fourth post on NoSQL database:
Introduction to NoSQL
Document Databases
Key-Value Databases
Graph Databases
1 — Introduction to NoSQL
NoSQL is an approach to database design that can accommodate a wide variety of data models, including key-value, document, columnar and graph formats. NoSQL, which stands for “not only SQL,” is an alternative to traditional relational databases in which data is placed in tables and data schema is carefully designed before the database is built. NoSQL databases are especially useful for working with large sets of distributed data.
The NoSQL term can be applied to some databases that predated the relational database management system (RDBMS), but it more commonly refers to the databases built in the early 2000s for the purpose of large-scale database clustering in cloud and web applications. In these applications, requirements for performance and scalability outweighed the need for the immediate, rigid data consistency that the RDBMS provided to transactional enterprise applications.
NoSQL helps deal with the volume, variety, and velocity requirements of big data:
Volume: Maintaining the ACID properties (Atomicity, Consistency, Isolation, Durability) is expensive and not always necessary. Sometimes, we can deal with minor inconsistencies in our results. We thus want to be able to partition our data multiple sites.
Variety: One single fixed data model makes it harder to incorporate varying data. Sometimes, when we pull from external sources, we don’t know the schema! Furthermore, changing a schema in a relational database can be expensive.
Velocity: Storing everything durable to a disk all the time can be prohibitively expensive. Sometimes it’s okay if we have a low probability of losing data. Memory is much cheaper now, and much faster than always going to disk.
There is no single accepted definition of NoSQL, but here are its main characteristics:
It has quite a flexible schema, unlike the relational model. Different rows may have different attributes or structure. The database often has no understanding of the schema. It is up to the applications to maintain consistency in the schema including any denormalization.
It also is often better at handling really big data tasks. This is because NoSQL databases follow the BASE (Basically Available, Soft state, Eventual consistency) approach instead of ACID.
In NoSQL, consistency is only guaranteed after some period of time when writes stop. This means it is possible that queries will not see the latest data. This is commonly implemented by storing data in memory and then lazily sending it to other machines.
Finally, there is this notion known as the CAP theorem — pick 2 out of 3 things: Consistency, Availability, and Partition tolerance. ACID databases are usually CP systems, while BASE databases are usually AP. This distinction is blurry and often systems can be reconfigured to change these tradeoffs.
We’ll discuss different categories of NoSQL, including document stores, key-value databases, and graph databases.

2 — Document Databases

There are many different document databases systems, such as MongoDB, FoundationDB, RethinkDB, MarkLogic, ArangoDB… There is no standard system; however, they all have to deal with a data type known as JSON. It is taken from JavaScript and contains objects, strings, numbers, arrays, booleans, and null in a nested dictionary.

The most popular document database is MongoDB, which is open-source and stores data in flexible, JSON-like documents, meaning fields can vary from document to document and data structure can be changed over time. The MongoDB hierarchy starts out with the database, then a collection, then a document.
The query below creates a new collection or view. Because MongoDB creates a collection implicitly when the collection is first referenced in a command, this method is used primarily for creating new collections that use specific options. For example, you use db.createCollection() to create a capped collection or to create a new collection that uses document validation.

MongoDB also uses document types known as BSON, which is a binary serialization format used to store documents and make remote procedure calls. Each BSON type has both integer and string identifiers as listed in the following table:

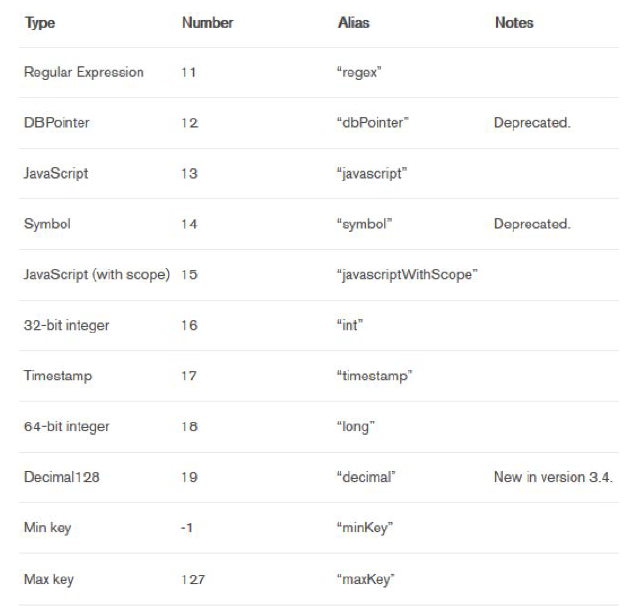
You can use these values with the $type operator to query documents by their BSON type. The $type aggregation operator returns the type of an operator expression using one of the listed BSON type strings.
The query below inserts a value into a document.

The query below inserts multiple documents into a collection.

MongoDB provides the capability to perform schema validation during updates and insertions. Validation rules are on a per-collection basis. To specify validation rules when creating a new collection, use db.createCollection() with the validator option.

Let’s walk through a real scenario. As seen below, we use MongoDB to retrieve the data from the bills database under the following conditions:
The patient is 376–97–9845.
Address’s zip code is 14534.
The amount is greater than or equal to 750.
The amount is greater than or equal to 750 AND address’s zip code is 14534.
The amount is greater than or equal to 750 OR address’s zip code is 14534.

You can find a bunch of different MongoDB query operators below. Let’s start with comparison operators: eq, gt, gte, in, lt, lte, ne, and nin.

Here we have boolean operators: and, not, nor, and or.

Now we have element and evaluation operators: exists, type, mod, regex, text, and where.

Finally we have array and bitwise operators: all, elemMatch, size, bitsAllClear, bitsAllSet, bitsAnyClear, and bitsAnySet.

Here’s how to do projection in MongoDB:

It says that we want to find the patient with the particular value of “376–97–9845”, and we only want the patient and id attributes from it. A corresponding SQL query is shown below:

Here’s how to do sorting in MongoDB:

It says that we want to sort the bills table, ordered by patient ascending and zip code descending. A corresponding SQL query is shown below:

Here’s how to update documents in MongoDB:

It says that we want to update the bills table with new values for zip code and city, where the patient has value “376–97–9845”. A corresponding SQL query is shown below:

Here’s how to remove documents in MongoDB:

It says that we want to remove from the bills table the instance where the patient has value “376–97–9845”. A corresponding SQL query is shown below:

Let’s discuss how to do aggregation in MongoDB. Below is the MongoDB’s code structure to do a projection, when we want to pass along the documents with the requested fields to the next stage in the pipeline. The specified fields can be existing fields from the input documents or newly computed fields.

The $project takes a document that can specify the inclusion of fields, the suppression of the _id field, the addition of new fields, and the resetting of the values of existing fields. Alternatively, you may specify the exclusion of fields.

Below is the MongoDB’s code structure to do match values, when we want to filters the documents to pass only the documents that match the specified condition(s) to the next pipeline stage.
The $match takes a document that specifies the query conditions. The query syntax is identical to the read operation query syntax, meaning that $match does not accept raw aggregation expressions. Instead, we can use a $expr query expression to include aggregation expression in $match.
Below is the MongoDB’s code structure to group values together, when we want to group documents by some specified expression and outputs to the next stage a document for each distinct grouping. The output documents contain an _id field which contains the distinct group by key. The output documents can also contain computed fields that hold the values of some accumulator expression grouped by the $group’s _id field. Note that $group does not order its output documents.

The _id field is mandatory; however, you can specify an _id value of null to calculate accumulated values for all the input documents as a whole. The remaining computed fields are optional and computed using the <accumulator> operators.
Let’s walk through an example of how MongoDB does grouping:

From the orders table, we match all the orders with “A” status. Then, we group the remaining results by cust_id. Finally, we return the cust_id and sum of the amount as a result.
For your information, here are different accumulators that can go to a field:
$sum, $avg, $max, $min (sum, average, maximum, minimum).
$first, $last (first and last value in a group).
$push (array of all values in a group).
$addToSet (distinct array of group values).
$stdDevPop, $stdDevSamp (population and sample standard deviation).
We have one special case when it comes to the group stage, which is when the _id is null, as seen below. The equivalent SQL query is Select Avg(amount) From bills.

Let’s move on the lookup stage. It performs a left outer join to an unsharded collection in the same database to filter in documents from the “joined” collection for processing. To each input document, the $lookup stage adds a new array field whose elements are the matching documents from the “joined” collection. The $lookup stage passes these reshaped documents to the next stage.

The $lookup takes a document with the following fields:
from: Specifies the collection in the same database to perform the join with. The from collection cannot be sharded.
localField: Specifies the field from the documents input to the $lookup stage. $lookup performs an equality match on the localField to the foreignField from the documents of the from collection. If an input document does not contain the localField, the $lookup treats the field as having a value of null for matching purposes.
foreignField: Specifies the field from the documents in the from collection. $lookup performs an equality match on the foreignField to the localField from the input documents. If a document in the from collection does not contain the foreignField, the $lookup treats the value as null for matching purposes.
as: Specifies the name of the new array field to add to the input documents. The new array field contains the matching documents from the from collection. If the specified name already exists in the input document, the existing field is overwritten.
Here’s how to do look up in MongoDB:

It specifies that we want to lookup values from the bill tables joining with the patients table on the local field ‘patient’ and foreign field ‘_id’. A corresponding SQL query is shown below:


The last aggregation function we’ll discuss is the unwind stage. It deconstructs an array field from the input documents to output a document for each element. Each output document is the input document with the value of the array field replaced by the element.
3 — Key-value databases
A key-value database, or key-value store, is a data storage paradigm designed for storing, retrieving, and managing associative arrays, a data structure more commonly known today as a dictionary or hash table. Dictionaries contain a collection of objects, or records, which in turn have many different fields within them, each containing data. These records are stored and retrieved using a key that uniquely identifies the record, and is used to quickly find the data within the database. Some popular key-value databases in used these days are rediscovering, Amazon DynamoDB, Aerospace, RiakKV, ArangoDB etc.
In key-value databases, updates to the value for a single key are usually atomic. Furthermore, many key-value databases allow for transactions which use multiple keys. Also, values have limited structure.
The upsides about key-value databases are:
Key-value databases are generally easier to run in a distributed fashion.
Queries and updates usually very fast.
Any type of data in any structure can be stored as a value.
However, the downsides about key-value databases are:
Very simple queries (usually just get a value given a key, sometimes a range).
No referential integrity.
Limited transactional capabilities.
No schema to understand the data.
Let’s briefly look at the most popular key-value database: Redis. Redis is basically a huge distributed hash table with little structure to values. All values are identified by a key which is a simple string. If we want more structure in our keys, it has to be defined by our application (e.g., user 3 could have the key “user:3”).
Redis values are commonly in key-value stores, values are just an arbitrary blob of data. Redis (and some other key-value stores) allows some structure: lists, sets, and hashes.
Below are examples of how to insert data in Redis:

Below are examples of how to retrieve data in Redis:

So when should you use a key-value database?
When you need something really fast.
When your data does not have a lot of structure/relationships.
For simple caching of data which is pulled from another source.
4 — Graph databases
Lastly, let’s talk about graph databases. They rely on unbounded queries, which is where the search criteria are not particularly specific and are thus likely to return a very large result set. A query without a WHERE clause would certainly fall into this category, but let’s consider for a moment some other possibilities.

Let’s walk through some examples using Neo4j, one of the world’s leading graph database. Below you can see a node in Neo4j with information about person and patient:

In order to create a node, we use the code below which is similar to Java. We insert node attributes with Sandra as the first name.

We can also give our node internal IDs.

Two nodes can have a relationship. For example, the 2 nodes Patient and Doctor have a primary relationship which starts in 2015–08–23.

To represent such a relationship, we can create edges between nodes, as seen here.

Let’s say we have sample data shown here. We have a relational model with 3 tables (Patient, Doctor, Visit) and different relationships (Attends, Primary, Attended By, Supervises).

That query below is for a single node. The SQL equivalent is “SELECT last FROM Patient WHERE age > 30 ORDER BY last ASC”.

That query below is to do aggregation. The SQL equivalent is “SELECT AVG(salary) FROM Doctor WHERE age > 30”.

And that’s the end of this post on NoSQL! I hope you found this helpful and get a good grasp of the basics of document-based, key-value, and graph-based databases. If you’re interested in this material, follow the Cracking Data Science Interview publication to receive my subsequent articles on how to crack the data science interview process.