

The 104th episode of Datacast is my conversation with Ran Romano, the co-founder and VP of Engineering at Qwak - where he is focused on building the next-generation ML infrastructure for ML teams of various sizes.
Our wide-ranging conversation touches on his time in the Israeli army, his engineering experience at VMware, his time at Wix building their internal ML platform, his current journey with Qwak building an end-to-end ML engineering platform to automate the MLOps processes, the evolution of feature stores, the MLOps community in Israel, and much more.
Please enjoy my conversation with Ran!
Listen to the episode on these podcasting platforms: (1) Spotify, (2) Apple Podcasts, (3) Google Podcasts, (4) iHeartRadio, (5) Stitcher, and (6) Tune In
Key Takeaways
Here are the highlights from my conversation with Ran:
On His Early Interest in Technology
Before university, I was in the army for three years. It was with the Israeli Intelligence Corporation. That is where my inspiration for a high-tech career started. The intelligence department was the highest-density talent location or workplace I have been with. That inspired me to do something related to building technology. My title in the army was Technical Project Manager, and my role was to bridge the gap between the intelligence-oriented personnel and the technical folks who were building the system. Essentially, I was bridging that gap and translating their needs into actual systems.
I went on to get a BS and an MS at the university, focusing on the practical side of computer science and software engineering. One of my favorite courses was Introduction to Machine Learning, which sparked my interest in ML. Another course I loved was Computer Graphics - where we built small computer games with rendering engines. As someone with more backend experience, having a graphics course and building something that I could visualize was a cool experience.
On Joining Wix.com As A Data Infrastructure Engineer
Wix is a website-building company. It has a B2C business where customers can build their presence online. I joined the data engineering group because I wanted to get closer to the data and ML engineering side. In my previous VMware job, I mainly did backend engineering, so I wanted to get more involved with the data world.
Wix was a big name back then, with 100M+ customers and fancy data infrastructure. The company headquarters was in Israel, so I wanted to join them to be close to the base. I wanted to know what I was working on and what product I was delivering. There were many enterprises with development sites in Israel (Apple, Google, Microsoft, Facebook, Amazon), but I wanted to join an Israeli-based company where the business and the product teams are located here.
On Building Wix's Internal ML Platform
I joined the data infrastructure department, which was around five people at the time. I like to think about our department as a small B2B company inside Wix. Our customers were Wix's data consumers - around 250 data analysts and 100 data engineers at the time. The idea behind everything that we built is that we had to make everything self-service. We could not build a data infrastructure where every analyst who wanted to integrate a piece of data into the platform must come to us. We were a small team, and there was no way that we could scale with the business.
The entire mindset was self-service: how do we create a tool or a platform where no one should talk to us? For example, Wix has a restaurant component. Let us say you want to track the number of dishes placed via your restaurant. If you want to create an analytics functionality with the dish button, we will give you an SDK where the backend developer could implement this functionality. From there on, it should magically appear in Wix's data lake without our manual intervention. That required a lot of building internal tools for the backend engineering teams and the analysts. This was the general mindset for the data infrastructure.
After a year and a half, we started noticing a big gap that was coming up for the data scientists. The data science group at Wix was going fast, from around 20-30 people when I joined to around 60 people before I left. They had the same set of problems. They were going way too fast and lacked the proper infrastructure to deliver their models into production. So we thought: Okay, let us replicate the process. How can we, as an infrastructure group, give data scientists the tools to build, deploy, maintain, and monitor ML models in production with minimal engineering effort? That was the vision of Wix's ML platform. If a data scientist needed to talk to me to get his model into production, then I failed. He should not know that I exist.
Here are the main components of the platform:
The first part was data management. A big part of what we did was the feature store, a single discoverable source of truth for features. It was based on the concept we designed at the time of a single feature definition.
The second part was a CI/CD mechanism. This was the model repository and build/CI system based on MLflow. We were a very early adopter of MLflow. At the time, I remember going to the Data + AI conference when Databricks published MLflow. It fit a nice gap for us, so we put it in production really fast.
The third part was the UI, basically our management console. It was the central place for the data scientists to manage the features, the datasets, and the models they deploy via Wix's ML platform.
The fourth part, the more production leg of the platform, was the centralized prediction service. It was the backend API for the platform, acting as a gateway for the ML models and speaking different production protocols.
On The CI/CD Component
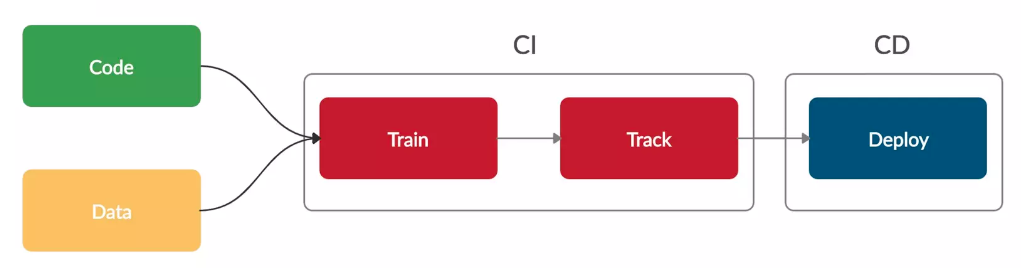
Source: https://www.slideshare.net/RanRomano/wixs-ml-platform
Let us zoom in on the CI/CD system. One of the problems we were trying to solve was the dependence between the data scientists and the ML engineers. I came to this problem as a software engineer myself, knowing that these engineers need a standardized way to deliver their models into production. At that time, the process was very manual. Data scientists trained models (usually on their local computers), created a Pickle file, handed over the notebooks to the engineers, and asked them to do something with that. We wanted to reduce the dependence by giving the data scientists a standard structure for delivering their models into production faster.
The idea is that they could create an interface, inherit from a certain base class, and use Wix's Build CI to generate a deployable Docker container (which they could deploy via API or the management console). That would create a model endpoint behind the prediction service, which exposes a REST and gRPC API that the larger Wix ecosystem could speak with. In brief, the CI/CD component helped them create a Build deployment system to automate the entire procedure.
On The Feature Store Component
The feature store idea came from two motivations:
Number one: We had a big project to predict premium and churn users. On every new model iteration, every time the model switched hands, there was an enormous effort around feature engineering. By feature engineering, I meant a lot of SQL scripts creating datasets and tables. The problem was that these SQL scripts were hard to maintain. They were not reproducible and could not be shared with other models deployed at the time. Predicting if a user will upgrade to premium or churn tends to use many of the same features. So there was no way to connect the features to reuse the exact feature definition. The idea was to create a single discoverable source of truth of features - a feature registry with the UI management console to control it. The scientists could understand which features have already been created and reused.
Number two: We wanted to eliminate the manual work that the engineering teams did in order to translate the features that the data scientists wrote in SQL into the production API. This was hard for online models. In many companies, data scientists build their features on top of analytical data sources - whether Snowflake, BigQuery, or Redshift. They create feature engineering pipelines - whether in SQL directly on top of the data warehouse, in Pandas, or whatever way. When they want to deploy that model, specifically as an online application, they must adapt those feature pipelines into a production flow. Suddenly, they do not have BigQuery or Snowflake in production. They need to answer every prediction request in order of milliseconds at the time so they can reuse that technology.
The question was: How to bridge that gap? How can the data scientists still have ownership of the feature engineering part? We created two legs for them - one for model training and the other for model serving. This was the general idea of creating a single feature definition that was discoverable, reusable, and shared during training and serving environments. A lot of the feature stores we are seeing today are highly materialized feature stores that persist all the data all the time on a dual-database architecture - saving the data in offline storage (Parquet, Delta Lake, Iceberg) and online key-value storage (Redis, Dynamo). At Wix, we took a different approach and built a virtual feature store, which materialized features only when requested, when we needed to generate the dataset, and when we wanted to create a real-time prediction.
On Lessons For Organizations Looking To Build An Internal ML Platform
1 - Software engineering practices do not always play well with ML:
I approached the ML engineering problem at the time from a software engineering perspective. The build is the concept that works exceptionally well for traditional software projects. Why shouldn't it work here? The notion of build means committing to Git, triggering a build operation, and getting a deployable image. It did work, but not to the naive notion I believed in.
Let us take, for example, the build process. My naive notion of doing ML build actually invokes a training procedure on every change to the model code that was pushed to Git. That notion was problematic because training is a process that data scientists usually tend to fully understand and want much more visibility. They want to optimize hyperparameters and run multiple builds in parallel. Not adapting the well-defined concepts in software engineering to the ML world was a key lesson that I specifically learned.
2 - Data management for online models is very challenging:
Adapting feature engineering processes to online models to meet production SLAs was a very challenging issue at Wix. This relates to the concept of a feature store, which is an evolving term: How do we create online features? How do we keep them aligned with the offline feature store? How do we mimic all the feature engineering parts that the data scientists do with Pandas? How do we understand if they scale well or meet latency requirements?
3 - Having a good way of monitoring model KPIs in production is crucial:
A good decision we made was always to have an eye on what the model is doing right now in production by logging the inputs and outputs of our models. The simple notion of logging every prediction request, transferring them into a data lake, and having it queryable by SQL was very valuable. This was the basis for the entire iteration of gradually building and deploying models in production.
On Attributes of Exceptional Engineering Talent
I was actively looking for hunger - the willingness to win. At Wix, I managed data engineering teams in Israel and Ukraine. These engineers cared about what they were building. They wanted to be a part of the product and the thought process. They wanted to talk with users and understand the problem better. This is a critical quality of highly productive engineers I met with and people I am trying to recruit these days.
I want people who want to win and are good at what they do. As I gain more experience, I rely more on these types of personas with the ambition and willingness to do whatever it takes to make a customer happy or build the best product in time. These personal characteristics matter more than work experience, from my perspective.
On The Founding Story of Qwak
Qwak's other three co-founders started thinking about this space before I joined. The CTO, Yuval, came from AWS. The COO, Lior, came from the business side of AWS. The CEO, Alon, was the VP of data at Payoneer. They met and thought about the area they wanted to approach, where they could have an inherent advantage. They came to the ML production space due to Yuval and Alon's experience at AWS and Payoneer.
To validate their idea, they met with data science leaders at other companies and pitched them a Powerpoint system - showing that data scientists have a hard time being productive because they have trouble deploying models into production. Yuval, who worked briefly with me at Wix, approached me to get my thoughts on their idea. Given my experience building the ML platform at Wix, I shared their passion and understanding of the domain. It went quickly from there, and I joined Qwak as the fourth co-founder and VP of Engineering.
Alon and Lior are responsible for the sales, marketing, and go-to-market teams. Yuval and I are responsible for product and engineering - where I lead the product-related teams, and Yuval leads the infrastructure-related teams. Taking inspiration from the organizational structure at other companies, we have two engineering teams: one focused on MLOps and one focused on DataOps. Both teams have their own backend engineers, frontend engineers, product managers, etc.
On Capabilities of the Qwak Platform
We have two ways in which you can use or deploy Qwak:
The first way is a full SaaS version, where you use Qwak with your entire stack.
The second way is a hybrid solution with two planes: a control plane with your entire metadata and a data/model plane that hosts your models.
Let us look at the big components of the platform:
First is a Build System. Qwak is a full ML engineering platform with a focus on the production part. The idea of the Build System is to transform or build your ML code into a production-grade ML solution. This adds the traditional build process to ML models and allows data scientists to build immutable and tested production-grade artifacts. The central concept around that is the standardization of the ML project structure.
Second is a Serving layer, which addresses model deployment. We have three distinct ways of deploying a model: a batch process, a real-time endpoint, and a streaming application. The general idea is that you have one build and multiple deployment systems. You do not need to add any additional code or write any additional infrastructure if you want to deploy your model as a batch process as opposed to a streaming process. This is an important concept for us as we have seen it to be valuable to our customers - having an agnostic way of building a model with no relation to the deployment system.
Third is a Data Lake, which handles the data produced by the model. This is the observability layer of the model that records and transfers every invocation of your model to Qwak's Data Lake so that you know what the model is doing in production.
Fourth is Automations capabilities, which automate many of your processes. For example, you can build and deploy via the CLI or the UI; but in more complex or advanced use cases, you want to retrain and redeploy a model on a scheduling basis (every month or every week). You want to avoid going into the system in order to build and deploy manually. Our Automation capabilities build and deploy a model on a scheduling basis without the need for any orchestration tool.
Fifth is a Feature Store. Two first-class citizens that we have are the models (deployable entities) and features. The relation between models and features is very important, so the feature store is the first-class citizen inside the ML platform.
In summary, the Build system, the Serving layer, the Data Lake, the Feature Store, and the Automation are the building blocks of Qwak's platform.
On The Future of The Feature Store Ecosystem
We see companies handling rather well the simple version of a feature store meant to be used for batch or offline use cases. They have the concept of specialized data tables or data warehouses that persist features. Maybe they create the concept of a point-in-time to understand how the feature looks at different timelines. This is something that we see teams with a lot of data engineering horsepower doing well.
A big engineering challenge in that area is the move to online systems. That is a different ball game. It requires different know-how, as it is not just a data engineering challenge anymore. It is also a production challenge and belongs to a software engineer's domain. You need to build a data store that serves real-time production traffic. You do not have the power of data warehouses or frameworks that data engineers are used to working with. As a result, the transition of building a feature store for batch use cases into a feature store for online (and even streaming) use cases is a big challenge. This effort requires building a major system.
I am starting to see feature stores become first-class citizens in companies' ML platforms. Customers are trying to adopt this - first, the CI/CD and analytic solutions, and then the feature store-like solution. Feature stores will be adopted much sooner because companies will have many more online use cases for their models. Having online use cases without a feature store and deploying multiple models with multiple versions at scale is a very challenging task. Even if you do not have the concept of a feature store, you need to have an online version of your data. You need to have an offline version of your data very fast - ideally with a dual database architecture that persists features in some way.
On Hiring
We want to attract and work with people who understand the impact of what the ML platform can do for an organization. We also go after people with a level of hunger who want to be part of a strong team and work at a fast pace on interesting problems. Of course, there are benefits to working in large corporations. I am not saying anything bad about working for Microsoft, Google, or Facebook. Developing some solution under that umbrella can be super interesting. But at the end of the day, you are doing something very small, usually for a big company, that does not suit anyone.
Some people, like myself, want to be part of something smaller and be involved with the entire lifecycle of product development - from engineering to sales. Typically in large corporations, these opportunities are less available.
On The MLOps Community in Israel
We used a lot of personal relationships with other companies in Israel as initial design partners. I must say that the Israeli ecosystem is simply amazing. I was unaware of that until I went out and experienced it firsthand. Many people have said: "Listen, no problem. I know that you are very early and have nothing to show yet. But let us start. Let us build something together and understand which position you want to be in. I will be your design partner."
Some companies like to work with small Israeli startups in that way to push the Israeli ecosystem forward. This is super valuable to the ecosystem because these startups will have to approach larger and tougher markets during later stages - where they have no personal relationships to rely on. At those stages, their product would be more mature to show.
The MLOps community in Israel is booming. We have many companies in the ML monitoring space, a few doing feature stores, and a few providing ML platforms like Qwak. This community is generally young compared to the cybersecurity market in Israel, where we have many unicorns. This matches the industry as a whole since there are not many unicorn startups in MLOps. It is still a relatively new field, with many players trying to earn their customers' trust.
Show Notes
(01:34) Ran reflected on his time working as a Technical Product Manager at the Israeli Intelligence army.
(04:07) Ran recalled his favorite classes on Machine Learning and Computer Graphics during his education in Computer Science at Reichman University.
(05:24) Ran talked about a valuable lesson learned as a Software Engineer at VMware's Cloud Provider Software Business Unit.
(08:07) Ran shared his thoughts on how engineers could be more impactful in startup organizations.
(09:52) Ran talked about his decision to join Wix.com to work as a software engineer focusing on data infrastructure.
(12:48) Ran explained the motivation for building Wix's internal ML platform, designed to address the end-to-end ML workflow.
(16:48) Ran discussed the main components of Wix's ML platform: feature store, CI/CD mechanism, UI management console, and API prediction service.
(18:51) Ran unpacked the virtual feature store and the CI/CD components of Wix's ML platform.
(24:41) Ran expanded on the distinction between virtual and materialized feature stores.
(27:01) Ran provided three key lessons for organizations looking to build an internal ML platform (as brought upon his 2020 talk discussing Wix's ML Platform).
(31:43) Ran shared the essential attributes of exceptional data and ML engineering talent.
(33:54) Ran shared the founding story of Qwak, which aims to build an end-to-end ML engineering platform to automate the MLOps processes.
(37:07) Ran talked about his responsibilities as the VP of Engineering at Qwak.
(38:45) Ran dissected the key capabilities that are baked into the Qwak platform - a Build System, a Serving layer, a Data Lake, a Feature Store, and Automations capabilities.
(44:05) Ran explained the big engineering challenges for teams to build an in-house feature store and envisioned the future of the feature store ecosystem in the upcoming years.
(47:45) Ran shared valuable hiring lessons to attract the right people who are excited about Qwak's mission.
(50:22) Ran reflected on the challenges for Qwak to find the early design partners.
(52:43) Ran described the state of the ML Engineering community in Israel.
(54:53) Closing segment.
Ran's Contact Info
Qwak's Resources
Mentioned Content
Talks
People
Book
"Principles" (by Ray Dalio)
Qwak’s ML Platform and Feature Store empower data science and ML engineering teams to continuously build, train and deploy ML models to production at scale.
By abstracting the complexities of model deployment Qwak brings agility and high-velocity to all ML initiatives designed to transform business, innovate, and create a competitive advantage. Qwak allows data teams to focus on the science
Read more at www.qwak.com
About the show
Datacast features long-form, in-depth conversations with practitioners and researchers in the data community to walk through their professional journeys and unpack the lessons learned along the way. I invite guests coming from a wide range of career paths — from scientists and analysts to founders and investors — to analyze the case for using data in the real world and extract their mental models (“the WHY and the HOW”) behind their pursuits. Hopefully, these conversations can serve as valuable tools for early-stage data professionals as they navigate their own careers in the exciting data universe.
Datacast is produced and edited by James Le. For inquiries about sponsoring the podcast, email khanhle.1013@gmail.com.
Subscribe by searching for Datacast wherever you get podcasts, or click one of the links below:
If you’re new, see the podcast homepage for the most recent episodes to listen to, or browse the full guest list.













