
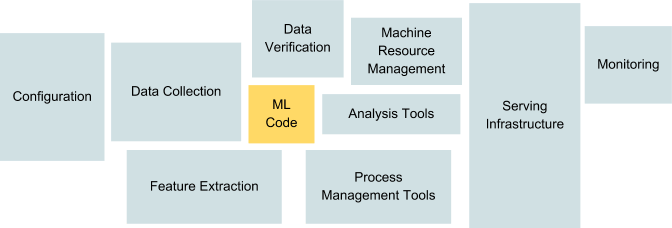
Sculley et al. — “Hidden Technical Debt in Machine Learning Systems” (https://ai.google/research/pubs/pub43146)
The picture above (from the famous Google’s paper “Machine Learning: The High-Interest Credit Card of Technical Debt”) shows that the portion of ML code in a real-world ML system is a lot smaller than the infrastructure needed for its support. As ML projects move from small-scale research experiments to large-scale industry deployments, your organization most likely will need a huge amount of infrastructure to support large inferences, distributed training, data processing pipelines, reproducible experiments, model monitoring, etc. So as a data scientist and/or machine learning engineer, how can you enable your teams/colleagues to focus on training models and presenting results without getting bogged down in machine learning technical debt?
I recently attended the Full-Stack Deep Learning Bootcamp in the UC Berkeley campus, which is a wonderful course that teaches full-stack production deep learning. One of the lectures delivered by Sergey Karayev provided a comprehensive overview of current infrastructure and tooling for deep learning use cases in the real world.
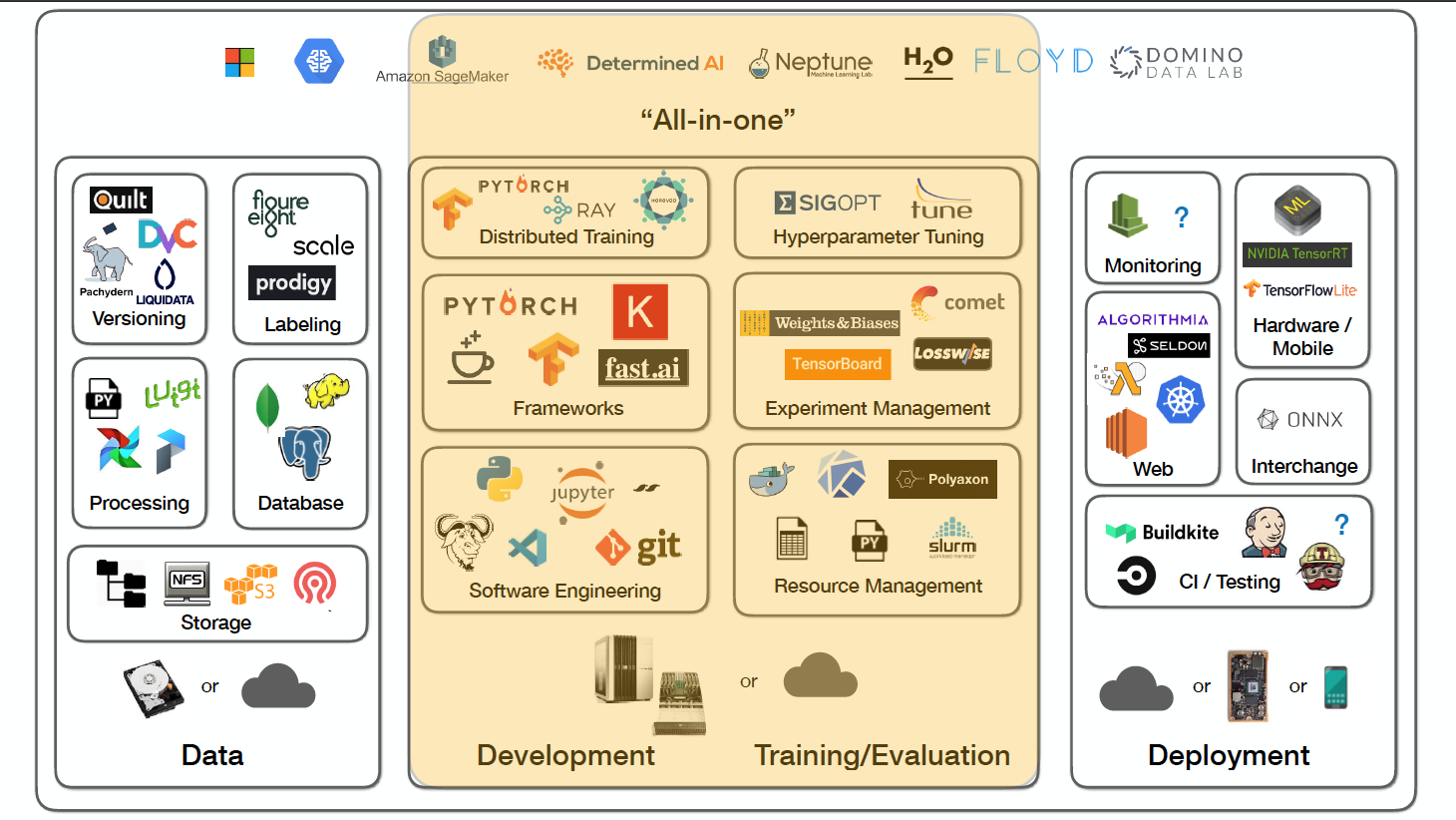
Sergey Kareyev at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
In this blog post, I would like to share the 7 questions that you and your Deep Learning colleagues should ask to handle deep learning technical debt. I will also provide the answers as well as a ton of resources, as a courtesy of Sergey’s lecture. As you can see from the picture above, these questions fall into the following categories: Software Engineering, Resource Management, Frameworks, Experiment Management, Distributed Training, Hyperparameter Tuning, and “All-In-One” Solutions.
1 — How Do I Write Deep Learning Code?
When it comes to writing deep learning code, Python is the clear programming language of choice. It was developed in the late 80s and is broadly utilized over the IT business and permits simple effort of collaboration inside development groups.
As a general-purpose language, Python is easy to learn and easily accessible, which enables you to find skilled developers on a faster basis.
It has a variety of scientific libraries for data wrangling and machine learning (Pandas, NumPy, Scikit-Learn…)
Regardless of whether your engineering colleagues write code in a lower-level language like C, C++, or Java, it is generally neat to join different components with a Python wrapper.
When it comes to choosing your IDEs, there are many options out there (Vim, Emacs, Sublime Text, Jupyter, VS Code, PyCharm, and Atom). Each of these has its uses in any application and you’re better to switch between them to remain agile without relying heavily on shortcuts and packages. It also helps teams to work better if an individual can jump into different IDEs and comment/collaborate with other colleagues.
Visual Studio Code makes for a very nice Python experience, with features such as built-in git staging and diffing, peek documentation, linter code hints… It also comes bundled with the Anaconda Navigator platform for Data Science, which is a sign of huge growth to come and a reason to be excited about VS Code.
PyCharm is a popular choice for Python developers. Its shortcut keys are powerful, as the IDE is built specifically for the Python language.
I personally use Atom, a lightweight product developed by GitHub. Its default shortcuts are fewer and more basic, but highly customizable.

The Netflix Tech Blog, Beyond Interactive: Notebook Innovation at Netflix (https://medium.com/netflix-techblog/notebook-innovation-591ee3221233)
However, Jupyter Notebooks have rapidly grown in popularity among data scientists to become the standard for quick prototyping and exploratory analysis. For example, Netflix based all of their machine learning workflows on them, effectively building a whole notebook infrastructure to leverage them as a unifying layer for scheduling workflows.
However, there are many problems with using notebooks as a last resort when working in teams that aim to build machine/deep learning products. In his blog post, Alexander Mueller outlines the 5 reasons why they suck:
It is challenging to enable good code versioning because notebooks are big JSON files that can’t be merged automatically.
Notebook “IDE” is primitive, as they have no integration, no lifting, and no code-style correction. Data scientists are not software engineers and thus, tools that govern their code quality and help to improve it are very important.
It is very hard to structure code reasonable, put code into functions, and develop tests while working in notebooks. You better develop Python scripts based on test-driven development principles as soon as you want to reproduce some experiments and run notebooks frequently.
Notebooks have out-of-order execution artifacts, meaning that you can easily destroy your current working state when jumping between cells of notebooks.
It is also difficult to run long or distributed tasks. If you want to handle big datasets, better to pull your code out of notebooks, start a Python folder, create fixtures, write tests, and then deploy your application to a cluster.
Very recently, an application framework called Streamlit was introduced. The creators of the framework wanted machine learning engineers to be able to create beautiful apps without needing a tools team; in other words, these internal tools should arise as a natural byproduct of the machine learning workflow. According to the launch blog post, here are the core principles of Streamlit:
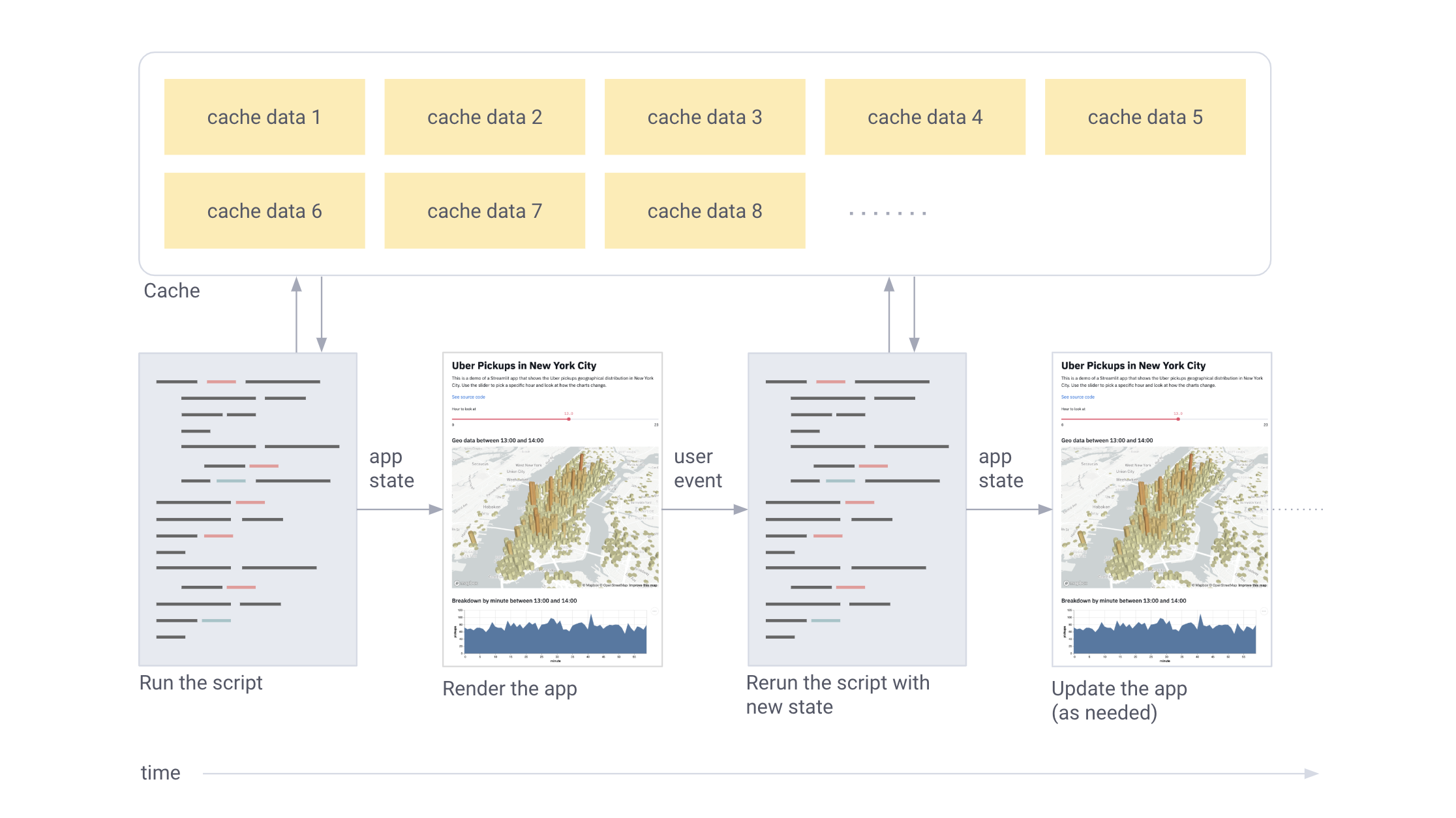
Adrien Treuille, Turn Python Scripts into Beautiful Machine Learning Tools (https://towardsdatascience.com/coding-ml-tools-like-you-code-ml-models-ddba3357eace)
Embrace Python scripting: Streamlit apps are really just scripts that run from top to bottom. There’s no hidden state. You can factor your code with function calls. If you know how to write Python scripts, you can write Streamlit apps.
Treat widgets as variables: There are no callbacks in Streamlit. Every interaction simply reruns the script from top to bottom. This approach leads to a really clean codebase.
Reuse data and computation: Streamlit introduces a cache primitive that behaves like a persistent, immutable-by-default, data store that lets Streamlit apps safely and effortlessly reuse information.
I am personally very excited to use Streamlit for my current projects. It makes sharing machine learning projects as easy as pushing a web app to Heroku.
2 — How Do I Effectively Manage Compute Resources?
Deep learning in the industry needs to respond to users’ complex and real-world problems. Especially for big companies that serve millions of businesses around the world, the deep learning infrastructure scores hundreds of millions of predictions across many deep learning models. These models are powered by billions of data points, with hundreds of new models being trained each day. Over time, the volume, quality of data, and the number of signals have grown enormously as the models continuously improve in performance.
Running infrastructure at such a scale poses a very practical deep learning problem: how to give every team the tools they need to train their models without requiring them to operate their own infrastructure? Each team also needs a stable and fast deep learning pipeline to continuously update and train new models as they respond to a rapidly changing world. The ultimate goal here is to make it easy to launch a batch of experiments across teams with proper dependencies and resource allocations.
There exists a variety of solutions, ranging from using spreadsheets to software specialized for Machine Learning use cases. The most primitive approach is to use spreadsheets that allow people to reserve what resources they need to use. Spreadsheets are easy to visualize and easy to convey to external parties. However, things get trickier once you have multiple people working on the same problems/tools. Some ground rules would need to be set prior to the project execution, else resource allocation will become cumbersome.
The next approach is to utilize SLURM Workload Manager, a free and open-source job scheduler for Linux and Unix-like kernels. It provides 3 key functions: (1) allocating exclusive and/or non-exclusive access to resources to users for some duration of time so they can perform work; (2) providing a framework for starting, executing, and arbitrating contention for resources by managing a queue of pending jobs. The scheduler can be scripted pretty easily, so would be handy for teams with strong programming skills.

A very standard approach these days is to use Docker alongside Kubernetes. Docker is a way to package up an entire dependency stack in a lighter-than-a-Virtual-Machine package. Kubernetes is a way to run many Docker containers on top of a cluster. I will go in more detail on this approach with a future post on model deployment but take a look at this article from Ben Weber if you’re interested in using Docker and Kubernetes to host Machine Learning models. If you write most of your code on Jupyter Notebooks, take a look at JupyterHub — a nice project that allows users to interact with a computing environment through a webpage. You can deploy JupyterHub on Kubernetes and leverage the cloud scalable nature to support large groups of users.
The last option is to use open-source projects. There are two projects associated with Kubernetes that I want to highlight: Kubeflow and Polyaxon.

Michal Brys, Kubeflow — a machine learning toolkit for Kubernetes (https://medium.com/@michal.brys/kubeflow-a-machine-learning-toolkit-for-kubernetes-d8686f6c91b6)
Kubeflow is an open-source and cloud-native platform for machine learning based on Google’s internal machine learning pipelines. Using Kubeflow allows you to run TensorFlow jobs at scale on containers with the same scalability as containers and container orchestration that comes with Kubernetes. This project is still under heavy development and requires a large investment of engineering time into understanding the system, configuring it for your needs, and often patching a few areas you need but no one has touched recently to make the most of everything in a truly integrated fashion, and to support multiple users dynamically.
Polyaxon is another open-source platform for building, training, and monitoring large-scale deep learning applications. It deploys into any data center, cloud provider, or can be hosted and managed by Polyaxon, and it supports all the major deep learning frameworks. Polyaxon is somewhat more aligned to the goals of a self-service multi-user system, taking care of scheduling and managing jobs in order to make the best use of available cluster resources. It also handles code/model versioning, automatic creation, and deployment of docker images, and can support auto-scaling. Most importantly, it turns GPU servers into shared, self-service resources for your team/organization.
3 — How Do I Choose A Deep Learning Framework?
I wrote a blog post last year discussing the 5 deep learning frameworks every serious machine learning researchers should be familiar with. In that one, I argued that with Theano no longer being developed, Torch written in the unfamiliar language Lua, and Caffe being in its precocious state, TensorFlow and PyTorch emerge as the preferred frameworks of most deep learning practitioners. Unless you have a good reason not to, you should use either one of them.
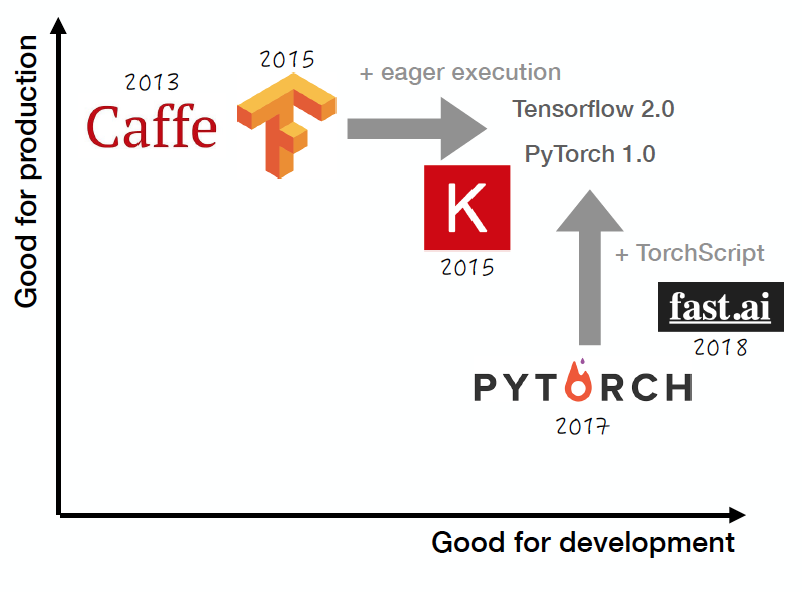
Sergey Kareyev at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
I also mentioned that PyTorch is better for rapid prototyping for hobbyists and small-scale projects, while TensorFlow is better for large-scale deployments, especially when cross-platform and embedded deployment are considerations. Nowadays, both frameworks are converging to the same ideal point: (1) easy development via define-by-run; and (2) multi-platform optimized execution graph. Another good option is fast.ai, which is worth starting with if you want to learn both basic and advanced deep learning skills. You will be able to implement the latest deep learning strategies easily and to iterate quickly.
There are a couple of comprehensive analyses that compare TensorFlow and PyTorch that I want to highlight. In Horace He’s detailed analysis of the state of machine learning frameworks in 2019, researchers are abandoning TensorFlow and flocking to PyTorch in droves. Meanwhile, in industry, TensorFlow is currently the platform of choice, but that may not be true for long. He gives the edge to PyTorch. Given that machine learning is a research-driven field, the industry can’t afford to ignore research output, and as long as PyTorch dominates research, that will pressure companies to switch.

Jeff Hale, Which Deep Learning Framework is Growing Fastest? (https://towardsdatascience.com/which-deep-learning-framework-is-growing-fastest-3f77f14aa318)
In another post that explores the landscape of deep learning frameworks, Jeff Hale looks at the number of job listings and evaluate changes in Google Search volume, GitHub activity, Medium articles, ArXiv articles, and Quora topic followers. He concluded that TensorFlow is both the most in-demand framework and the fastest growing, so it’s not going anywhere anytime soon. PyTorch is growing rapidly too, as its large increase in job listings is evident in its increased usage and demand. However, he said that PyTorch is more Pythonic, has a more consistent API, and shares many commands with NumPy.
4 — How Do I Enable Distributed Training For My Models?
One of the major reasons for the sudden boost in deep learning’s popularity has to do with massive computational power. Deep learning requires training neural networks with a massive number of parameters on a huge amount of data. Distributed computing, therefore, is a perfect tool to take advantage of the modern hardware to its fullest. If you’re not familiar with distributed computing, it’s a way to program software that uses several distinct components connected over a network.
Distributed training of neural networks can be approached in 2 ways: (1) data parallelism and (2) model parallelism.
Data parallelism attempts to divide the dataset equally onto the nodes of the system, where each node has a copy of the neural network along with its local weights. Each node operates on a unique subset of the dataset and updates its local set of weights. These local weights are shared across the cluster to compute a new global set of weights through an accumulation algorithm. These global weights are then distributed to all the nodes, and the processing of the next batch of data comes next.
Model parallelism attempts to distribute training by splitting the architecture of the model onto separate nodes. It is applicable when the model architecture is too big to fit on a single machine and the model has some parts that can be parallelized. Generally, most networks can fit on 2 GPUs, which limit the amount of scalability that can be achieved.
Practically, data parallelism is more popular and frequently employed in large organizations for executing production-level deep learning algorithms. PyTorch offers a very elegant and easy-to-use API as an interface to the underlying MPI library written in C. You can follow the PyTorch tutorials on using DataParallel and DistributedDataParallel if you want to get familiar with that. Model Parallelism, on the other hand, is only necessary when a model does not fit on a single GPU. This approach introduces a lot of complexity and is usually not worth it. It is better to buy the largest GPU you can afford.

Eric Xing et. al., Petuum: A New Platform for Distributed Machine Learning on Big Data (https://arxiv.org/pdf/1312.7651.pdf)
If you want to take advantage of both of these methods, I would highly recommend checking out the paper Petuum: A New Platform for Distributed Machine Learning on Big Data from Carnegie Mellon. Petuum is a distributed ML platform built around the characteristics of ML algorithms: iterative and non-uniform convergence, error tolerance, and dynamic structure. Its computation model is designed to support both data and model parallelism.
Another option is Ray, an open-source project for effortless, stateful, parallel, and distributed computing in Python. Ray allows you to run the same code on more than one machine, build microservices and actors that have state and can communicate, handle machine failures gracefully, and address large objects efficiently. Take a look at this document to see how Ray simplifies distributed model training for PyTorch.

Finally, we have Horovod, Uber’s open-source distributed deep learning framework for Tensorflow, Keras, PyTorch, and Apache MXNet. The framework uses MPI (standard multi-process communication framework) instead of Tensorflow parameter servers, so it can be an easier experience for multi-node training. In terms of ease of use, there are only a few commands to inject into standard training code in order to support training in this way — standard optimizers are wrapped in a custom distributed version. Uber has been working hard to improve Horovod, from adding examples of very large models to sharing learnings about adjusting model parameters for distributed deep learning; so I’d definitely recommend you giving it a try.
5 — How Do I Keep Track Of My Experiments?
Getting your models to perform well is a very iterative process. You most likely have to run a bunch of experiments, change the underlying models, try different optimizers and hyperparameters, change the sampling methods, split train/validation/test multiple times, try different libraries/packages, etc. You may also run multiple experiments on multiple GPUs/hosts to parallelize the process and each of them might have different hardware specs.
If you don’t have a system for managing your experiments, it quickly gets out of control. You will forget what worked, what did not work, and why they worked. This is such a big problem, which has spawned a few companies/tools solely dedicated to solving just this issue. Below I introduce a couple of options.
TensorBoard is a TensorFlow extension that allows you to easily monitor your model in a browser. To provide an interface from which you can watch the model’s process, TensorBoard also offers some options useful for debugging. For example, you can observe the distributions of the model’s weights and gradients during training. If we really want to dig into the model, TensorBoard offers a visual debugger. In this debugger, you can step through the execution of the TensorFlow model and examine every single value inside it. This is especially useful if you are working on complex models and are trying to understand why complex things break down.

Cecelia Shao, CometML Cheat Sheet: Supercharge Your Machine Learning Workflow (https://medium.com/comet-ml/comet-ml-cheat-sheet-supercharge-your-machine-learning-experiment-management-7786e08f8e9e)
Comet.ml is another platform built for Machine Learning that enables engineers and data scientists to efficiently maintain their preferred workflow and tools, while easily tracking previous work and collaborating throughout the iterative process. It has native support for ML frameworks like TensorFlow, Keras, PyTorch, MXNet, and more. I recommend you to take a look at this cheat sheet and explore getting started with the platform.
Losswise provides ML practitioners with an intuitive and elegant Python API and accompanying dashboard to visualize progress within training sessions as well as across training sessions. It’s ideal for running model comparison experiments, as well as simply tracking one-off training scripts. Its documentation is plentiful to get you started.
Weights & Biases is an experiment tracking tool for deep learning. It allows you to do 3 things: (1) storing all the hyper-parameters and output metrics in one place to effortlessly track runs and reproduce models; (2) exploring and comparing every experiment with training/inference visualizations to see trends across individual and multiple runs; and (3) creating beautiful reports that showcase your work to seamlessly collaborate and communicate findings with your team. Check out the comprehensive documentation from its website.
Databricks, Introduction to MLflow (https://www.slideshare.net/databricks/introduction-fo-mlflow)
MLflow is an open-source platform for the entire machine learning lifecycle started by Databricks. It tackles 3 primary functions: experimentation, reproducibility, and deployment. In particular, its MLflow Tracking component is an API and UI for logging parameters, code versions, metrics, and output files when running your ML code and for later visualizing the results. This utility lets you log and query experiments using Python, R, REST, and Java APIs.
6 — How Do I Tune My Model Hyper-parameters?
Hyper-parameter tuning is an art in and of itself. Deep learning models are literally full of hyper-parameters (parameters that define the model architecture); thus finding the best configuration for these variables in a high-dimensional space is not trivial. Searching for hyper-parameters is an iterative process constrained by computing power, money, and time. Therefore, it would be really useful to have software that helps you search over hyper-parameter settings.
If you want to dig deeper into the mathematical aspect of hyper-parameter optimization, check out Jeremy Jordan’s in-depth blog post. He shared the 3 major methods that you can use to tune the model hyperparameters:
Grid search is the most basic method. With this technique, you simply build a model for each possible combination of all of the hyper-parameter values provided, evaluating each model, and selecting the architecture which produces the best results.
Random search differs from grid search in that you no longer provide a discrete set of values to explore for each hyper-parameter. Instead, you provide a statistical distribution for each hyper-parameter from which values may be randomly sampled.
Bayesian search allows you to use the results from previous iterations to improve your sampling method of the next experiment.
Next, I’d like to share a couple of nice hyper-parameter optimization libraries which are free and open-source.
Hyperopt is a Python library for serial and parallel optimization over awkward search spaces, which may include real-valued, discrete, and conditional dimensions. Currently, it offers 3 algorithms: Random Search, Tree of Parzen Estimators (TPE), and Adaptive TPE. It has been designed to accommodate Bayesian optimization algorithms based on Gaussian processes and regression trees, but these are not currently implemented. All algorithms can be parallelized in 2 ways using either Apache Spark or MongoDB.
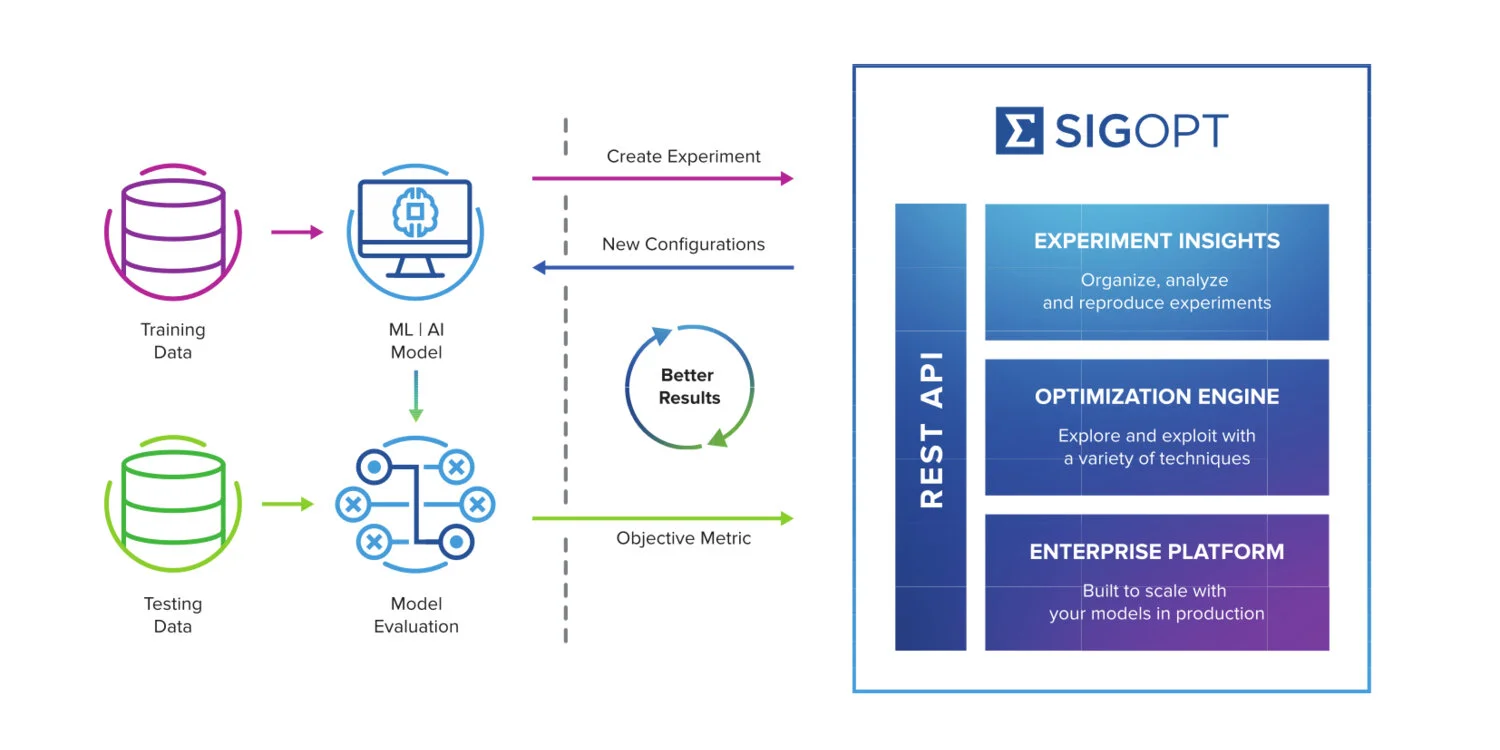
Nick Payton, Automating Model Tuning and Hyperparameter Optimization with SigOpt (https://aws.amazon.com/blogs/awsmarketplace/automating-model-tuning-and-hyperparameter-optimization-with-sigopt/)
SigOpt is an optimization-as-a-service API that allows users to seamlessly tune the configuration parameters in AI and ML models. It optimizes models through a combination of Bayesian and global optimization algorithms, which allows users and companies to boost the performance of their models while cutting costs and saving the time that might have been previously spent on more tedious, conventional tuning methods. Some of the advantages of SigOpt’s service include its ease of use: it can be easily integrated on top of any existing workflow, and its graphical interface also simplifies the process. It also uses what the company calls “black box optimization” — meaning the API doesn’t need access to the underlying data to optimize it, meaning that companies’ ML models and intellectual property are kept private. SigOpt also allows users to tune any algorithm in parallel by performing as a “distributed scheduler” for parameter tuning so that serially arranged models can be tuned in parallel so that better results are achieved faster across a larger scale.
Tune is a Python library for hyper-parameter tuning at any scale, developed under the open-source project Ray we discussed in section 5. It allows you to choose among scalable State-Of-The-Art algorithms such as Population Based Training, Vizier’s Median Stopping Rule, and HyperBand. It also integrates with many optimization libraries and enables you to scale them transparently. And, you can visualize your results with TensorBoard.

Sayak Paul, Running Hyperparameter Sweeps to Pick the Best Model (https://www.wandb.com/articles/running-hyperparameter-sweeps-to-pick-the-best-model-using-w-b)
Lastly, Weights & Biases (discussed in the last section) has a nice feature called “Hyperparameter Sweeps” — a way to efficiently select the right model for a given dataset using the tool. The sweeps organize search in a very elegant way, allowing you to set up the searches using declarative configurations and experiment with a variety of tuning methods including grid search, random search, Bayesian optimization, and Hyperband. Check out this tutorial from their website for a nice demo on the FashionMNIST dataset.
7 — How Do I Decide Between Building or Buying Machine Learning Platforms?
You might wonder whether your organization should build in-house or buy an off-the-shelf platform to execute a deep learning project. Generally speaking, if the statements below are true, then your organization should invest in a machine learning platform, which enables you to get the benefits of deep learning without the costs of building and maintaining a deep learning infrastructure.
You would benefit from training data outside of the data you already own.
You want to implement and scale machine learning-based functionality for your product or service easily and without much time and resources taken from your current team.
The budget needed to build an in-house machine learning platform could be more helpful for building out other areas of business, such as sales or marketing.
Machine learning is an add-on to your current business or product offering and not the core of what you do or sell.
Below I want to introduce a couple of well-known “All-In-One” machine learning platforms currently used in the industry, which provide a single system for everything: development (hosted notebook), scaling experiments to many machines (sometimes even provisioning), tracking experiments and versioning models, deploying models, and monitoring model performance.
Amazon SageMaker is one of the core AI offerings from AWS that helps teams through all stages in the machine learning life cycle. It provides a simple Jupyter Notebook UI that can be used to script basic Python code. It can build models trained by data dumped into the S3 buckets, or a streaming data source like Kinesis shards. Once models are trained, SageMaker deploys them into production without any effort. SageMaker is especially helpful when you need to retrain your model periodically and serve your model as a web service. For training, SageMaker can automatically start a high-performance EC2 instance and finish model training within a short time at the minimum cost. For web serving, SageMaker can take care of auto-scaling and make sure your endpoint is always available. To use SageMaker for Machine Learning, the most important step is to prepare a script that defines the behaviors of your model. And you also have full control of the whole system by creating your own Docker container.
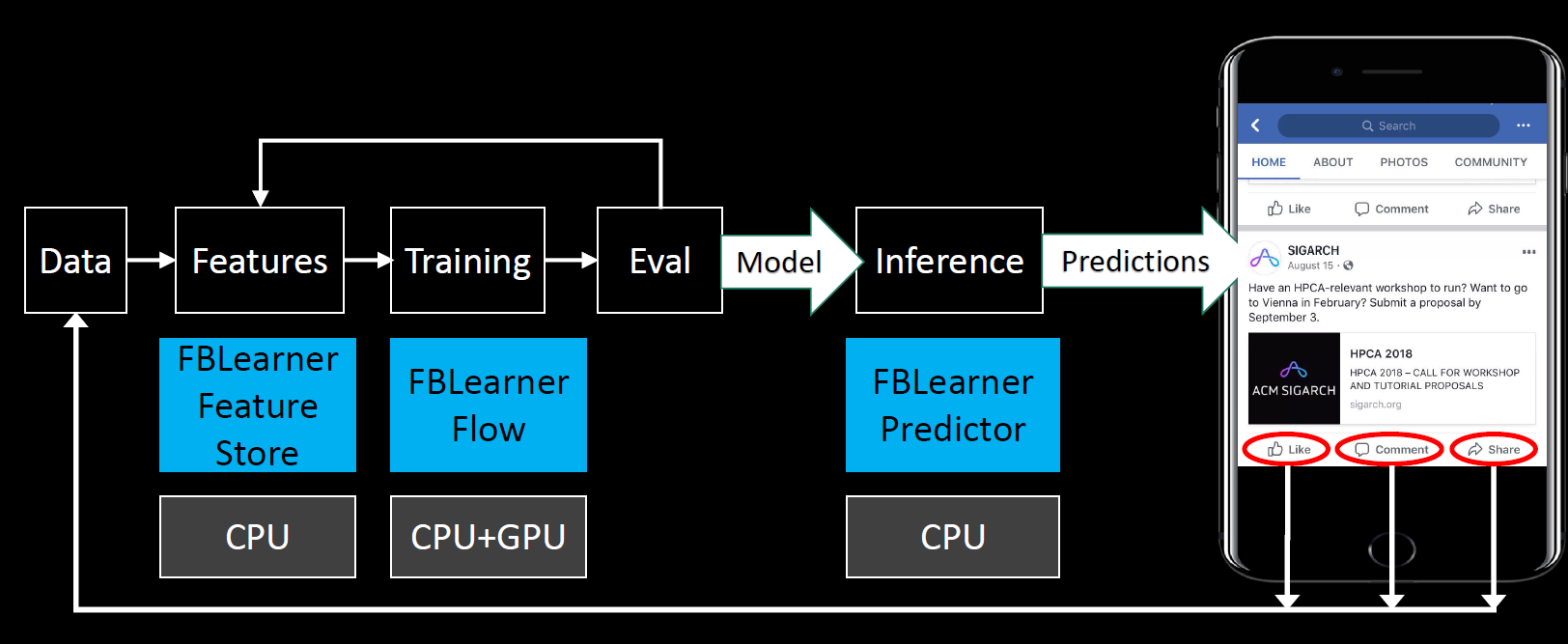
Yangqing Jia, ML at Facebook: An Infrastructure View (https://www.matroid.com/scaledml/2018/yangqing.pdf)
FBLearner Flow is the workflow management platform at the heart of the Facebook ML engineering ecosystem. It is capable of easily reusing algorithms in different products, scaling to run thousands of simultaneous custom experiments, and managing experiments with ease. It also provides innovative functionality, like automatic generation of UI experiences from pipeline definitions and automatic parallelization of Python code using features. I’d recommend listening to this TWIMLAI podcast interview with the Engineering Manager at Facebook to learn the history and development of the platform, as well as its functionality and its evolution from an initial focus on model training to supporting the entire ML lifecycle at Facebook.
TensorFlow Extended (TFX) is a Google-production-scale ML platform based on TensorFlow. It provides a configuration framework to express ML pipelines consisting of TFX components. There are 4 components in total: (1) TF Data Validation — a library for analyzing and validating data used for the model; (2) TF Transform — a library for engineering input features; (3) TF Model Analysis — a library for evaluating models and viewing metrics/plots in a notebook; and (4) TF Serving — a library for serving models and handling inferences at scale. TFX components interact with an ML Metadata backend that keeps a record of component runs, input and output artifacts, and runtime configuration. This metadata backend enables advanced functionality like experiment tracking or warm-starting/resuming ML models from previous runs. Its tutorial page is a good place to start.
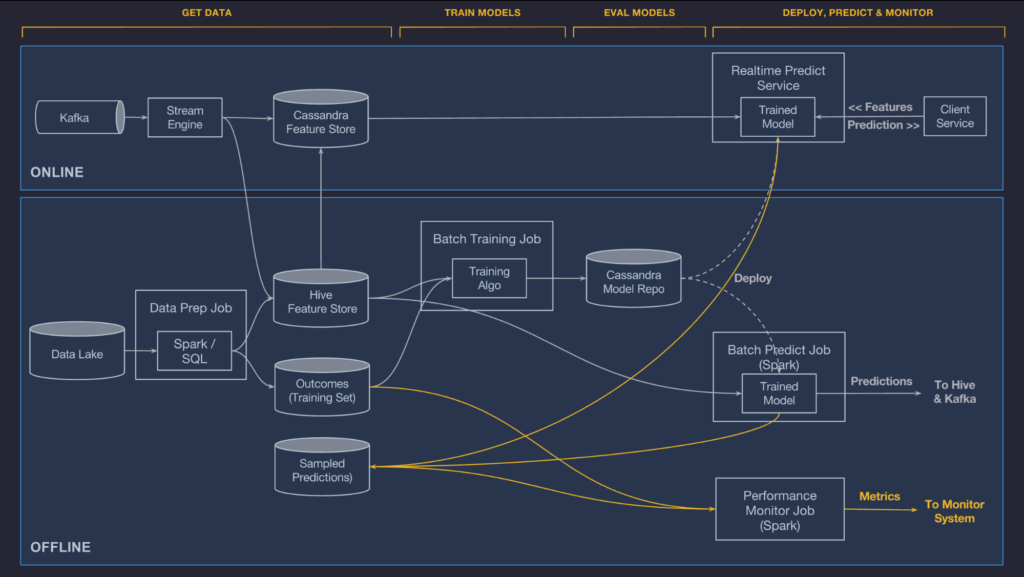
Jeremy Hermann and Mike Del Balso, Meet Michelangelo: Uber’s Machine Learning Platform (https://eng.uber.com/michelangelo/)
Michelangelo, Uber’s ML Platform, supports the training and serving of thousands of models in production across the company. Designed to cover the end-to-end ML workflow, the system currently supports classical ML, time series forecasting, and deep learning models that span a myriad of use cases ranging from generating marketplace forecasts, responding to customer support tickets, to calculating accurate estimated times of arrival, and powering NLP models on the driver app. The engineering team at Uber has done a tremendous amount of development since the platform’s introduction 3 years ago, including training ML models at scale, allowing rapid Python model development, and evolving model representation for flexibility with Spark MLib. I’d recommend listening to this TWIMLAI podcast interview with the PM for ML platforms at Uber for more information.
Another option from Google is its Cloud AI Platform, a managed service that enables you to easily build machine learning models, that work on any type of data, of any size. You can create your model with TensorFlow, build models of any size with Google’s managed scalable infrastructure. Your trained model is immediately available for use with Google’s global prediction platform that can support thousands of users and TBs of data. The service is integrated with Google Cloud Dataflow for pre-processing, allowing you to access data from Google Cloud Storage, Google BigQuery, and others.

How to use Floyd to train your models (https://www.youtube.com/watch?v=OJsirsSBX-A)
FloydHub is one of my favorite managed cloud platforms for data scientists. This is because of the awesome technical blog that the company has. Here are a couple of good articles that are worth checking out: Colorizing Black and White Photos with Neural Nets, Turning Design Mockups Into Code With Deep Learning, DeOldify: Colorizing and Restoring Old Images and Videos with Deep Learning, and Recommending Similar Fashion Images with Deep Learning. Regarding the platform itself, here are some neat features: (1) Launching a GPU-enabled workspace in 1-click to start building in seconds; (2) Using the command-line interface to run and monitor reproducible experiments; and (3) Deploying and scaling models based on needs and with an auto-generated web page.
Neptune is a relatively new player in this ecosystem. According to its website, it is a product that spun off in 2018 from the deepsense.ai team, which focuses on managing the experimentation process while remaining lightweight and easy to use by any data science team. Thanks to Nepture, the ML team at DeepSense was able to get rid off spreadsheets for keeping history of executed experiments and their metrics values; eliminate sharing source code across the team as an email attachment; limit communication required to keep track of project progress and achieved milestones; and unify visualization for metrics and generated data. If you want to get started, check out Neptune’s docs to learn how to run an experiment, track it online, and use basic client features.

Rachel Rapp, Introducing Gradient Community Notebooks: Easily Run ML Notebooks on Free GPUs (https://blog.paperspace.com/paperspace-launches-gradient-community-notebooks/)
If you have done any of the courses from fast.ai before, you are probably familiar with Paperspace. This YC-backed startup provides a solution for accessing computing power via the cloud and offers it through an easy-to-use console where everyday consumers can just click a button to log into their upgraded, more powerful remote machine. Last year, they introduced Gradient — a suite of tools designed to accelerate cloud machine learning. It includes a powerful job runner, first-class support for containers and Jupyter notebooks, and a set of language integrations. There is a whole library of sample projects that you can clone and run in your own account. Recently, there is a new feature called Community Notebooks that allow users to run ML notebooks on free GPUs, which is definitely appealing.
Determined AI is a startup that creates software to handle everything from managing cluster compute resources to automating workflows, thereby putting some of that big-company technology within reach of any organization. The solution is based on research conducted over the past few years at UC Berkeley’s AmpLab (best known for developing Apache Spark). Its integrated AutoML platform simplifies the entire deep learning workflow from data management to model training and deployment. It manages your heterogeneous hardware and optimizes your GPU resource utilization.

Open Data Science | Domino Data Lab (https://www.dominodatalab.com/solutions/open-data-science/)
Lastly, Domino Data Lab is a platform built to support modern data analysis workflows. Domino is language agnostic (supports Python, R, MATLAB, Perl, Julia, shell scripts and more) and has rich functionality for version control and collaboration (think Github for data science) along with one-click infrastructure scalability (think Heroku for scripts), and deployment and publishing — all in an integrated end-to-end platform. The company has a ton of nice resources including white papers, guides and reports, blog posts, and videos/webinars to get you started.
Conclusion
If you want to get a nice summary of this piece, take a look at section 2 (Development, Training, and Evaluation) of this GitHub repo on Production Level Deep Learning, created by Alireza Dirafzoon (another Full-Stack Deep Learning attendee). Hopefully, this article has presented helpful information for you to operate deep learning infrastructure at a scalable and reliable level. In the upcoming blog posts, I will share more lessons that I learned from attending the Full-Stack Deep Learning Bootcamp, so stay tuned!