
One of the best articles I have read about data science in 2019 is “Data science is different now” by Vicki Boykis. Part of the article is basically a collection of tweets from other data science and machine learning practitioners.
The article confirms that data science has never been as much about machine learning as it has about cleaning, shaping data, and moving it from place to place. Along with data cleaning, what’s become more clear as the hype cycle continues its way to productivity is that data tooling and being able to put models into production has become even more important than being able to build ML algorithms from scratch on a single machine, particularly with the explosion of the availability of cloud resources.

Sergey Kareyev at Full Stack Deep Learning Bootcamp November 2019 (https://fullstackdeeplearning.com/november2019/)
I recently attended the Full-Stack Deep Learning Bootcamp in the UC Berkeley campus, which is a wonderful course that teaches full-stack production deep learning. One of the lectures delivered by Sergey Karayev provided nice coverage of data management. In this blog post, I would like to share the 5 concepts in managing data to ensure their eventual quality as inputs for your machine learning models.
1 — Data Sources
So where do the training data come from? Most deep learning applications require lots of labeled data (with exceptions in domains such as reinforcement learning, GANs, and “semi-supervised” learning. There are publicly available datasets that can serve as a starting point, but there is no competitive advantage of doing so.
Most companies usually spend a lot of money and time to label their own data (which will be covered below). Alternatively, there are 2 other approaches that have proven to be effective: self-supervised learning and data augmentation.
Self-supervised learning is a relatively recent learning technique where the training data is autonomously (or automatically) labeled. It is still supervised learning, but the datasets do not need to be manually labeled by a human, but they can e.g. be labeled by finding and exploiting the relations (or correlations) between different input signals (that is, input coming from different sensor modalities).
A natural advantage and consequence of self-supervised learning are that it can more easily (with respect to e.g. supervised learning) be performed in an online fashion (given that data can be gathered and labeled without human intervention), where models can be updated or trained completely from scratch. Therefore, self-supervised learning should also be well suited for changing environments, data and, in general, situations.

A great summary of how self-supervised learning tasks can be constructed (Image source: LeCun’s talk)
For example, we might rotate images at random and train a model to predict how each input image is rotated. The rotation prediction task is made-up, so the actual accuracy is unimportant, like how we treat auxiliary tasks. But we expect the model to learn high-quality latent variables for real-world tasks, such as constructing an object recognition classifier with very few labeled samples.
If you’re interested in learning more about self-supervised learning, check out this comprehensive post from Lillian Weng.
Recent advances in deep learning models have been largely attributed to the quantity and diversity of data gathered in recent years. Data augmentation is a strategy that enables practitioners to significantly increase the diversity of data available for training models, without actually collecting new data. Data augmentation techniques such as cropping, padding, and horizontal flipping are commonly used to train large neural networks. In fact, they are mostly required for training computer vision models. Both Keras and fast.ai provide functions that do this.
Data augmentation also applies to other types of data. For tabular data, you can delete some cells to simulate missing data. For text, there are no well-established techniques, but you can replace words with synonyms and change the order of things. For speech and video, you can change speed, insert a pause, mix different sequences, etc.

Edward Ma, Data Augmentation for NLP (https://github.com/makcedward/nlpaug)
Related to this concept of data augmentation is synthetic data, an underrated idea that is almost always worth starting with. Synthetic data is data that’s generated programmatically. For example photorealistic images of objects in arbitrary scenes rendered using video game engines or audio generated by a speech synthesis model from the known text. It’s not unlike traditional data augmentation where crops, flips, rotations, and distortions are used to increase the variety of data that models have to learn from. Synthetically generated data takes those same concepts even further.
Most of today’s synthetic data is visual. Tools and techniques developed to create photorealistic graphics in movies and computer games are repurposed to create the training data needed for machine learning. Not only can these rendering engines produce arbitrary numbers of images, but they can also produce the annotations, too. Bounding boxes, segmentation masks, depth maps, and any other metadata is output right alongside pictures, making it simple to build pipelines that produce their own data.
Because samples are generated programmatically along with annotations, synthetic datasets are far cheaper to produce than traditional ones. That means we can create more data and iterate more often to produce better results. Need to add another class to your model? No problem. Need to add another key point to the annotation? Done. This is especially useful for applications in driving and robotics.

Open AI — Ingredients for Robotics Research (https://openai.com/blog/ingredients-for-robotics-research/)
2 — Data Labeling
Data labeling requires a collection of data points such as images, text, or audio and a qualified team of people to label each of the input points with meaningful information that will be used to train a machine learning model. Broadly speaking, there are 3 approaches to label proprietary data at scale.
You can create a user interface with a standard set of features (bounding boxes, segmentation, key points, cuboids, set of applicable classes…) and train your own annotators to label the data. Note that training the annotators is crucial to ensure a high quality of labeled data.
You can leverage other labor sources by either hiring your own annotators or crowding the annotators (Mechanical Turk). Hiring people is secure, fast (once hired), and requires less quality control; but is also expensive, slow to scale, and has much administrative overhead. In contrast, crowdsourcing is cheaper and more scalable; but also not secure and requires significant quality control effort.
You can also consult standalone service companies. Data labeling requires separate software stack, temporary labor, and quality assurance; so it makes sense to outsource. You should dedicate at least several days to selecting the best options for you: (1) Label gold standard data yourself, (2) Make sales call with several contenders and ask for work sample on the same data, and (3) Ensure an agreement with your gold standard and evaluate on the value. Most popular data labeling companies are Figure Eight, Scale, Labelbox, and Supervisely.

Supervisely Product Page (https://supervise.ly/product/)
In brief, you should outsource data labeling to a full-service company if you can afford it. If not, then you should at least use an existing annotation tool (for example, Prodigy). And lastly, hiring part-time annotators makes more sense than trying to make crowdsourcing work.
3 — Data Storage
Data storage requirements for AI vary widely according to the application and the source material. Medical, scientific and geological data, as well as imaging data sets used in intelligence and defense, frequently combine petabyte-scale storage volumes with individual file sizes in the gigabyte range. By contrast, data used in areas such as supply chain analytics and fraud detection are much smaller. Broadly speaking, there are 4 building blocks in a data storage system:
The filesystem is the foundational layer of storage. Its fundamental unit is a “file” — which can be text or binary, is not versioned, and is easily overwritten. A filesystem can be as simple as a locally mounted disk containing all the files you need. More advanced options include networked filesystems (NFS) which are accessible over the network by multiple machines and distributed filesystem (HDFS) which are stored and accessed over multiple machines.
Object storage is an API over the filesystem that allows users to use a command on files (GET, PUT, DELETE) to a service, without worrying where they are actually stored. Its fundamental unit is an “object” — which is usually binary (images, sound files…). Object storage can be built with data versioning and data redundancy in mind. It can be parallel, but not fast. Two well-adopted solutions are Amazon S3 and Ceph.
The database is a persistent, fast, and scalable storage/retrieval of structured data. Its fundamental unit is a “row” (unique IDs, references to other rows, values in columns). The database is built usually for data that will be accessed again (not logs). Popular options include MongoDB, MySQL, and PostgreSQL (which I recommend whole-heartedly because of its best-in-class SQL, vibrant community, and great support for unstructured JSON).
Finally, a data lake is the unstructured aggregation of data from multiple sources (databases, logs, expensive data transformations). It operates under the concept of “schema-on-read” by dumping everything in and then transforming the data for specific needs later.
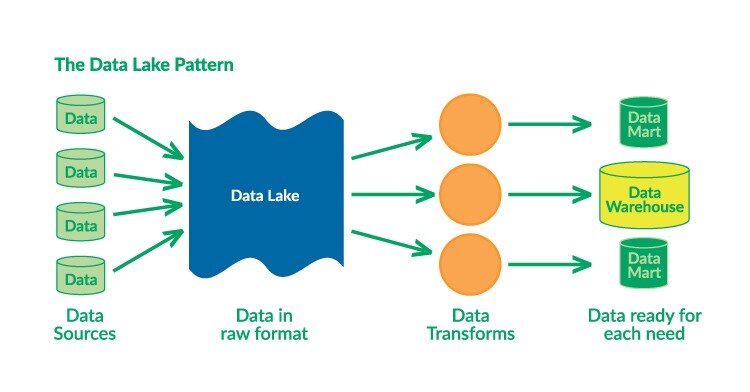
DataKitchen — Throw Your Data in a Lake (https://medium.com/data-ops/throw-your-data-in-a-lake-32cd21b6de02)
So what goes where?
Binary data (images, sound files, compressed texts) are stored as objects.
Metadata (labels, user activity) is stored in a database.
If we need features that are not obtainable from the database (logs), we would want to set up data lake and a process to aggregate needed data.
At training time, we need to copy the data that is needed onto the filesystem (either local or networked).
A highly recommended resource is Martin Kleppmann’s book “Designing Data-Intensive Applications” — which provides nice coverage of tools and approaches to build reliable, scalable, and maintainable data storage systems.
4 — Data Versioning
Data versioning refers to saving new copies of your data when you make changes so that you can go back and retrieve specific versions of your files later. There are 4 levels of data versioning maturity:
In Level 0, the data lives on the filesystem and/or object storage and the database without being versioned. The big problem here is that if data is not versioned, then deployed models are also not versioned since the models are part code, part data. If your deployed models are not versioned, then you won’t be able to get back to a previous level of performance.
In Level 1, the data is versioned by storing a snapshot of everything at training time. This allows you to version deployed models, and to get back to past performance but is a super hacky trick. It would be far better to be able to version data just as easily as code.
In Level 2, the data is versioned as a mix of assets and code. Heavy files can be stored in object storage with unique IDs. Training data can be stored as JSON or similar, referring to the above IDs and include relevant metadata (labels, user activity, etc.) Note that these JSON files can get big, but using git-lfs lets you store them just as easily as code.
Level 3 requires specialized solutions for versioning data. You should avoid these until you can fully explain how they will improve your project. Leading solutions are DVC (an open-source version control system for ML projects), Pachyderm (a tool for production data pipelines), and Dolt (Git for Data).

DVC’s Data Versioning Tutorial (https://dvc.org/doc/tutorials/versioning)
5 — Data Workflow
Let’s look at a motivational example of training a photo popularity predictor every night. For each photo, the training data must include these components:
Metadata (such as posting time, title, location) that is in the database
Some features of the user (such as how many times they logged in today) that needs to be computed from logs
Outputs of photo classifiers (such as content, style) that can be obtained after running the classifiers
The idea is that we have different sources of data and they have different dependencies. The big hurdle here is that some tasks can’t be started until other tasks are finished. The simplest thing we can do is a “Makefile” to specify what action(s) depend on. But here are some limitations to this approach:
What if re-computation needs to depend on content, not on a date?
What if the dependencies are not files, but disparate programs and databases?
What if the work needs to be spread over multiple machines?
What if there are 100s of “Makefiles” all executing at the same time, with shared dependencies?
That’s when you need a workflow management system. Airflow is the current winner of this space. In Airflow, a workflow is defined as a collection of tasks with directional dependencies, basically a directed acyclic graph (DAG). Each node in the graph is a task, and edges define dependencies among the tasks. Tasks belong to 2 categories: operators that execute some operation and sensors that check for the state of a process or a data structure.

Robert Sanders — Making Apache Airflow Highly Available (http://site.clairvoyantsoft.com/making-apache-airflow-highly-available/)
The main components of Airflow include: (1) a metadata database that stores the state of tasks and workflows, (2) a scheduler that uses the DAGs definitions together with the state of tasks in the metadata database to decide what needs to be executed, and (3) an executor that decides which worker will execute each task.
Conclusion
If you want to get a nice summary of this piece, take a look at section 1 (Data Management) of this GitHub repo on Production Level Deep Learning, created by Alireza Dirafzoon (another Full-Stack Deep Learning attendee). Hopefully, this article has presented helpful information for you to manage data the right way for machine learning use cases. In the upcoming blog posts, I will share more lessons that I learned from attending the Full-Stack Deep Learning Bootcamp, so stay tuned!