
Over the past few years, machine learning has grown tremendously. But as young as machine learning is as a discipline, the craft of managing a machine learning team is even younger. Many of today’s machine learning mangers were thrust into management roles out of necessity or because they were the best individual contributors, and many come from purely academic backgrounds. At some companies, engineering or product leaders are being tasked with building new machine learning functions without any real machine learning experience.
Running any technical team is hard:
You have to hire great people.
You need to manage and develop them.
You need to manage your team’s output and make sure your vectors are aligned.
You would want to make good long-term technical choices and manage technical debt.
You also must manage expectations from leadership.
Running a Machine Learning team is even harder:
Machine Learning talents are expensive and scarce.
Machine Learning teams have a diverse set of roles.
Machine Learning projects have unclear timelines and high uncertainty.
Machine Learning is also the “high-interest credit card of technical debt."
Leadership often doesn’t understand Machine Learning.
I recently attended the Full-Stack Deep Learning Bootcamp in UC Berkeley campus, which is a wonderful course that teaches full-stack production deep learning. One of the lectures delivered by Josh Tobin provided the best practices surrounding Machine Learning teams. As a courtesy of Josh’s lecture, this article will give you some insight into how to think about building and managing Machine Learning teams if you are a manager, and also possibly help you get a job in Machine Learning if you are a job seeker.
Note: You can also watch this lecture from Josh’s talks at the FSDL March 2019 version and the Applied Deep Learning Fellowship held at Weights & Biases.
1 - Defining The Roles
Let’s take a look at the most common Machine Learning roles and the skills they require:
The Machine Learning Product Manager is someone who works with the Machine Learning team, as well as other business functions and the end-users. This person designs docs, creates wireframes, comes up with the plan to prioritize and execute Machine Learning projects.
The DevOps Engineer is someone who deploys and monitors production systems. This person handles the infrastructure that runs the deployed Machine Learning product.
The Data Engineer is someone who builds data pipelines, aggregates and collects from data storage, monitors data behavior… This person works with distributed systems such as Hadoop, Kafka, Airflow.
The Machine Learning Engineer is someone who trains and deploys prediction models. This person uses tools like TensorFlow and Docker to work with prediction systems running on real data in production.
The Machine Learning Researcher is someone who trains prediction models, but often forward-looking or not production-critical. This person uses TensorFlow / PyTorch / Jupiter to build models and reports describing their experiments.
The Data Scientist is actually a blanket term used to describe all of the roles above. In some organizations, this role actually entails answering business questions via analytics.

Josh Tobin at FSDL Bootcamp Nov 2019 (https://fullstackdeeplearning.com/november2019/)
So what skills are needed for these roles? The chart above displays a nice visual, where the horizontal axis is the level of Machine Learning expertise and the size of the bubble is the level of communication and technical writing (the bigger the better).
The Machine Learning DevOps is primarily a software engineering role, which often comes from a standard software engineering pipeline.
The Data Engineer belongs to the software engineering team that works actively with Machine Learning teams.
The Machine Learning Engineer requires a rare mix of Machine Learning and Software Engineering skills. This person is either an engineer with significant self-teaching OR a science/engineering Ph.D. who works as a traditional software engineer after graduate school
The Machine Learning Researcher is a Machine Learning expert who usually has an MS or Ph.D. degree in Computer Science or Statistics or finishes an industrial fellowship program.
The Machine Learning Product Manager is just like a traditional Product Manager, but with a deep knowledge of the Machine Learning development process and mindset.
The Data Scientist role constitutes a wide range of backgrounds from undergraduate to Ph.D. students.
2 - Structuring The Team
There exists not yet a consensus on the right way to structure a Machine Learning team, but there are a few best practices that are contingent upon different organization archetypes and their Machine Learning maturity level. First, let’s see what are the different Machine Learning organization archetypes.
Archetype 1 - Nascent and Ad-Hoc ML
These are orgs in which no one is doing Machine Learning, or Machine Learning is done on an ad-hoc basis. Obviously, there is little Machine Learning expertise in-house.
These are either small-to-medium businesses or less technology-forward large companies in industries like education or logistics.
There is often low-hanging fruit for Machine Learning.
But there is little support for Machine Learning projects and it’s very difficult to hire and retain good talent.
Archetype 2 - Research and Development ML
These are orgs in which Machine Learning efforts are centered in the R&D arm of the organization. They often hire Machine Learning researchers and doctorate students with experience publishing papers.
These are larger companies in sectors such as oil and gas, manufacturing, or telecommunications.
They can hire experienced researchers and work on long-term business priorities to get big wins.
However, it is very difficult to get quality data. Most often, this type of research work rarely translates into actual business value, so usually the amount of investment remains small.
Archetype 3 - Product Embedded ML
These are orgs in which certain product teams or business units have Machine Learning expertise along-side their software or analytics talent. These Machine Learning individuals report up to the team’s engineering/tech lead.
These are either software companies or financial services companies.
Machine Learning improvements are likely to lead to business value. Furthermore, there is a tight feedback cycle between idea iteration and product improvement.
Unfortunately, it is still very hard to hire and develop top talent, and access to data & compute resources can lag. There are also potential conflicts between Machine Learning project cycles and engineering management, so long-term Machine Learning projects can be hard to justify.
Archetype 4 - Independent ML Division
These are orgs in which Machine Learning division reports directly to senior leadership. The Machine Learning Product Managers work with Researchers and Engineers to build Machine Learning into client-facing products. They can sometimes publish long-term research.
These are often large financial services companies.
Talent density allows them to hire and train top practitioners. Senior leaders can marshal data and compute resources. This gives the organizations to invest in tooling, practices, and culture around Machine Learning development.
A disadvantage is that model handoffs to different business lines can be challenging, since users need to buy-in to Machine Learning benefits and get educated on the model use. Also, feedback cycles can be slow.
Archetype 5 - ML-First
These are orgs in which the CEO invests in Machine Learning and there are experts across the business focusing on quick wins. The Machine Learning division works on challenging and long-term projects.
This group includes large tech companies and Machine Learning-focused startups.
They have the best data access (data thinking permeates the organization), the most attractive recruiting funnel (challenging Machine Learning problems tends to attract top talent), and the easiest deployment procedure (product teams understand Machine Learning well enough).
This type of organization archetype is hard to implement in practice since it is culturally difficult to embed Machine Learning thinking everywhere.

Depending on the above archetype that your organization resembles, you can make the appropriate design choices, which broadly speaking follow these 3 categories:
Software Engineer vs Research: To what extent is the Machine Learning team responsible for building or integrating with software? How important are Software Engineering skills on the team?
Data Ownership: How much control does the Machine Learning team have over data collection, warehousing, labeling, and pipelining?
Model Ownership: Is the Machine Learning team responsible for deploying models into production? Who maintains the deployed models?
Below are the design suggestions...
If your organization focuses on Machine Learning R&D:
Research is most definitely prioritized over Software Engineering skills. Because of this, there would potentially be a lacking of collaboration between these two groups.
Machine Learning team has no control over the data and typically will not have data engineers to support them.
Machine Learning models are rarely deployed into production.
If your organization has Machine Learning embedded into the product:
Software Engineering skills will be prioritized over Research skills. Often, the researchers would need strong engineering skills since everyone would be expected to product-ionize his/her models.
Machine Learning team generally does not own data production and data management. They will need to work with data engineers to build data pipelines.
Machine Learning engineers totally own the models that they deploy into production.
If your organization has an independent Machine Learning division:
Each team has a strong mix of engineering and research skills; therefore they work closely together within teams.
Machine Learning team has a voice in data governance discussions, as well as a strong data engineering function.
Machine Learning team hands-off models to user, but is still responsible for maintaining them.
If your organization is Machine Learning-First:
Different teams are more or less research-oriented; but in general, research teams collaborate closely with engineering teams.
Machine Learning team often owns the company-wide data infrastructure.
Machine Learning team hands-off models to user, who operates and maintains them.
The picture below neatly sums up these suggestions:

Josh Tobin at FSDL Bootcamp Nov 2019 (https://fullstackdeeplearning.com/november2019/)
3 - Managing The Projects
Manage Machine Learning projects can be very challenging:
According to Lukas Biewald, it is hard to tell in advance what’s hard and what’s easy. Even within a domain, performance can vary wildly.
Machine Learning progress is nonlinear. It is very common for projects to stall for weeks or longer. In the early stages, it is difficult to plan a project because it’s unclear whether what will work. As a result, estimating Machine Learning project timelines is extremely difficult.
There are cultural gaps between research and engineering because of different values, backgrounds, goals, and norms. In toxic cultures, the two sides often don’t value one another.
And often, leadership just does not understand it.
So how can you manage Machine Learning teams better? The secret sauce is to plan the Machine Learning project probabilistically!
In essence, going from this:

To this:
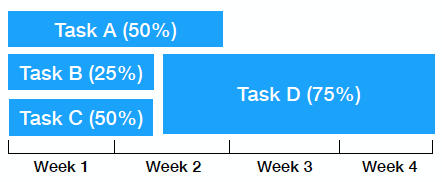
Here are some other good practices:
You should attempt a portfolio of approaches.
You should measure progress based on inputs, not results.
You should have researchers and engineers work together.
You should get end-to-end pipelines together quickly to demonstrate quick wins.
You should educate leadership on Machine Learning timeline uncertainty.
4 - Hiring The Talent
According to this 2019 Global AI Talent Report from Element AI, there is strong evidence that the supply of top-tier AI talent does not meet the demand. There were about 22,000 people at the cutting edge of AI research who are actively publishing papers and presenting at academic conferences. Only around 4,000 people contributed to research that had a major impact on the overall field. A total of 36,500 people qualified as self-reported AI specialists. Compared this to the number of software developers, which is 4.2 million in the US and 26.4 million in the world.
1 - How To Source Machine Learning Talent?
Here are some strategies to hire Machine Learning Engineers:
Hire people for their software engineering skills, keen interest in Machine Learning, and a desire to learn. You can then train them to do Machine Learning.
Go for junior roles, considering that most undergraduate Computer Science students these days graduate with Machine Learning experience.
Be really specific about what you need. For example, not every Machine Learning engineer needs to do DevOps.
And here are strategies to hire Machine Learning Researchers:
Look for the quality of publications, not the quantity (e.g., originality of ideas, quality of execution)
Look for researchers with an eye for working on important problems. Many researchers focus on trendy problems without considering why they matter.
Look for researchers with experience outside of academia.
Consider hiring talented people from adjacent fields such as math, physics, and stats.
Consider hiring people without Ph.D. degrees. For example, talented undergraduate and Master’s students, graduates of industrial fellowship programs (Google, Facebook, OpenAI), and even dedicated self-studiers.
How do you find these candidates in the first place?
There are standard sources such as LinkedIn, using a recruiting agency, and visiting universities’ career fairs.
You should attend well-known Machine Learning research conferences (NeurIPS, ICLR, ICML) for Machine Learning Researchers and well-known Applied Machine Learning conferences (O’Reilly, ReWork, TensorFlow World) for Machine Learning Engineers.
You can monitor ArXiv for impressive research papers and contact the first authors.

For a long-term strategy, you would want to think about how to attract these candidates and make your organization stand out:
Since Machine Learning practitioners want to work with cutting edge tools and techniques, your company should work on research-oriented projects, publicize them with blog posts, and invest in tooling & infrastructure for your Machine Learning team.
Since Machine Learning practitioners want to build skills and knowledge in an exciting field, your company should build a team culture around learning (i.e. reading groups, learning days, professional development budget, conference budget).
Since Machine Learning practitioners want to work with excellent people, your company should hire high-profile people and/or help your best people build their profile through publishing blogs and papers.
Since Machine Learning practitioners want to work on interesting datasets, your company should sell the uniqueness of your dataset in recruiting materials.
Since Machine Learning practitioners want to do work that matters, your company should sell the mission of your company and the potential impact of Machine Learning on that mission. More importantly, you should work on projects that have a tangible impact today.
2 - How to Interview Machine Learning Candidates?
So what should you test for in a Machine Learning interview?
The first thing is to validate your hypotheses of the candidate’s strengths. For Machine Learning Researchers, make sure that they can think creatively about new Machine Learning problems and probe how thoughtful they were about previous projects. For Machine Learning Engineers, make sure they are great generalists with solid engineering skills.
The second thing is to ensure that the candidates meet a minimum bar on weaker areas. For Machine Learning Researchers, test them engineering knowledge and ability to write good code. For Machine Learning Engineers, test them simple Machine Learning knowledge.
The Machine Learning interview is much less well-defined than a traditional software engineering interview, but here are common types of assessments:
Background and culture fit
Whiteboard coding
Pair coding / debugging (often Machine Learning-specific code)
Math puzzles
Take-home project
Applied Machine Learning (e.g., explain how to solve a problem with Machine Learning)
Previous projects (methodologies, trials and errors, findings)
Machine Learning theory (e.g., bias-variance tradeoff, overfitting and underfitting, specific algorithms…)

3 - How To Find A Job As a Machine Learning Practitioner?
Let’s say you are a Machine Learning candidate reading this article. You might ask: "Where do I look for a Machine Learning job?"
Again, there are standard sources like LinkedIn, recruiters, and on-campus recruiting.
You can attend Machine Learning research conferences and network with people there.
You can also just apply directly to the companies’ portal (remember that there’s a talent gap!)
The job search is certainly not easy, but there are a couple of ways to stand out:
Build general software engineering skills (via CS classes and/or work experience).
Exhibit interest in Machine Learning (via attending conferences and/or taking MOOCs).
Show that you have a broad knowledge of Machine Learning (e.g., write blog posts synthesizing a research area).
Demonstrate the ability to get Machine Learning projects done (e.g., create side projects and/or reimplement papers).
Prove you can think creatively in Machine Learning (e.g., win Kaggle competitions and/or publish papers).
In order to prepare for the interview, you should:
Practice for a general software engineering interview with resources like Cracking The Coding Interview.
Prepare to talk in detail about your past projects, including the tradeoffs and decisions you made.
Review Machine Learning theory and basic Machine Learning algorithms.
Think creatively about how to use Machine Learning to solve the problems that the company you’re interviewing with might face.
I would also recommend checking out this slide from Chip Huyen delivered at the Bootcamp, which includes some great lessons from both sides of the Machine Learning interview process.
Conclusion
Being a new and evolving discipline for most traditional organizations, forming machine learning teams is full of known and unknown challenges. If you skipped to the end, here are the final few take-homes:
There are lots of different skills involved in production Machine Learning, so there are opportunities for many people to contribute.
Machine Learning teams are becoming more standalone and more interdisciplinary.
Managing Machine Learning teams is hard. There is no silver bullet, but shifting toward probabilistic planning can help.
Machine Learning talent is scarce. As a manager, be specific about what skills are must-have in the Machine Learning job descriptions. As a job seeker, it can be brutally challenging to break in as an outsider, so use projects as a signal to build awareness.
Hopefully, this post has presented helpful information for you to build out machine learning teams productively. In the upcoming blog posts, I will share more lessons that I learned from attending the Full-Stack Deep Learning Bootcamp, so stay tuned!