
The science behind personalized travel experience
Wondering how Airbnb sorts and delivers its listings when you search for a place to stay on your next getaway? If you know anything about machine learning, you might have expected that there are a plethora of variables that go into sorting the tens of thousands of listings that are sometimes available in a specific location. Unlike machines, it’s impossible for one human being to go through each listing – and if you’re indecisive by nature, this could pose an existential problem. That’s why Airbnb’s machine learning algorithms do the work for you, pulling signals from a variety of data points, depending on whether you are host or guest.
Optimizing matches between hosts and guests will be critical to Airbnb's success as it continues to grow. The variety of types of accommodations Airbnb has is an advantage, as long as it ensures guests can easily find a host that meets their criteria. And as Airbnb adds to its 4 million current listings, ensuring both guests and hosts are satisfied will become more crucial. If users can find the exact accommodation they are looking for, especially if it is at a cheaper price, they are unlikely to revert to using hotels.
So how does Airbnb do such an amazing job of optimizing guest-host matching? After spending a couple of weeks digging up on Airbnb Technical Blog, I discover that there are 5 important use cases of machine learning that are currently being deployed by Airbnb’s engineers and data scientists to solve this problem. Here they are, in respective order of presentation:
- Detecting host's preferences
- Delivering insights to the hosts
- Predicting home values
- Fighting financial fraud
- Recommending personalized listings
1 - Detecting Host’s Preferences
The goal of this machine learning system is to discover what affects the hosts’ decisions to accept accommodation requests and how Airbnb could increase acceptances and matches on the platform. After doing initial data query and experiments, Airbnb found out that the hosts were more likely to accept requests that fit well in their calendar and minimize gap days. Additionally, hosts in big markets (such as San Francisco or New York City) care a lot about their occupancy; while for small markets, hosts prefer to have a small number of nights between requests. Thus, if Airbnb could promote in their search results those hosts who would be more likely to accept an accommodation request resulting from a potential guest’s search query, they would expect to see happier guests and hosts and more matches that turned into fun vacations or productive business trips.

At first glance, this seems like a perfect case for collaborative filtering — we have users (hosts) and items (trips) and we want to understand the preference for those items by combining historical ratings (accept/decline) with statistical learning from similar hosts. However, the application does not fully fit in the collaborative filtering framework for two reasons.
- First, no two trips are ever identical because behind each accommodation request there is a different guest with a unique human interaction that influences the host’s acceptance decision.
- Taking this point one step further, a host can receive multiple accommodation requests for the same trip with different guests at different points in time and give those requests conflicting votes.
Thus, Airbnb engineers and data scientists built a model resembling collaborative filtering. They used the multiplicity of responses for the same trip to reduce the noise coming from the latent factors in the guest-host interaction. To do so, they considered hosts’ average response to a certain trip characteristic in isolation. Instead of looking at the combination of trip length, size of the guest party, size of calendar gap and so on, they looked at each of these trip characteristics by itself.
For predictions, they combined the preferences for different trip characteristics into a single prediction for the probability of acceptance. The weight the preference of each trip characteristic has on the acceptance decision is the coefficient that comes out of the logistic regression. To improve the prediction, they also included a few more geographic and host-specific features in the logistic regression.
The flowchart summarizes the modeling technique used:

2 - Delivering Insights to Hosts
The goal of this machine learning system is to answer a very common question from Airbnb hosts: How do I pick the right price? Setting a price can be hard without reliable information about other listings in hosts’ area, travel trends, and the interest people have in the amenities hosts offer.
Thus, the team at Airbnb decided to build a model that can share insights that they learned with the hosts. An insight is a campaign that guides hosts to become more successful at pricing. Each insight must be personalized, targeted, and actionable.
To serve up the insights, they created Narad - a backend service that ingests data from a set of offline and online data sources to generate personalized insights, to rank their effectiveness for different listings and contexts, and to deliver insights at the right place and right time.

An insight generated by Narad consists of the following:
- Identifiers: This includes the insight type that is the identifier of each insight, the placement that tells which host tool this insight can be delivered to, and other grouping information.
- Targeting: This is a list of targeting conditions that need to be satisfied in order for the insight to be eligible for a given listing. There are various dimensions such as occupancy, past and future bookings, market demand, geography, listing attributes and pricing settings over which insights can be targeted.
- Payload: This determines a set of personalized information that the insight displays to the host. Example payloads range from the suggested values for host settings to the benefit of the host such as the potential booking increase.
- Copy: This contains the information to fetch the internationalized content for the UI.
Narad is responsible for delivering the most relevant and impactful insights to the host. The first iteration of ranking defines the total value of each insight through a set of terms. The first term is the weight which refers to the inherent impact of the insight. The second term is the historical conversion rate of the particular insight. Some insights might carry high impact but draw less attention from hosts. Other insights might get a lot of conversions but not be inherently impactful. The first term and the second term keep this balance. The last term is the repetition penalty that discounts the total value of the insight if the same insight was ranked as the top insight last time. This helps to provide some variance on the top position so that the same insight doesn’t appear at the top over and over even though it is the best insight in order to keep hosts more engaged.
3 - Predicting value of homes on Airbnb
At Airbnb, predicting home values is a specific use case of Customer Lifetime Value modeling, which captures the projected value of a user for a fixed time horizon. At marketplace companies like Airbnb, knowing users’ Lifetime Values enable them to allocate budget across different marketing channels more efficiently, calculate more precise bidding prices for online marketing based on keywords, and create better listing segments.
For Lifetime Value modeling, Airbnb developed machine learning tools that abstract away the engineering work behind product-ionizing machine learning models. In specific, there are 4 tasks in their ML workflow for this task:
- Feature Engineering
- Prototyping and Training
- Performing Model Selection
- Taking Model Prototypes to Production
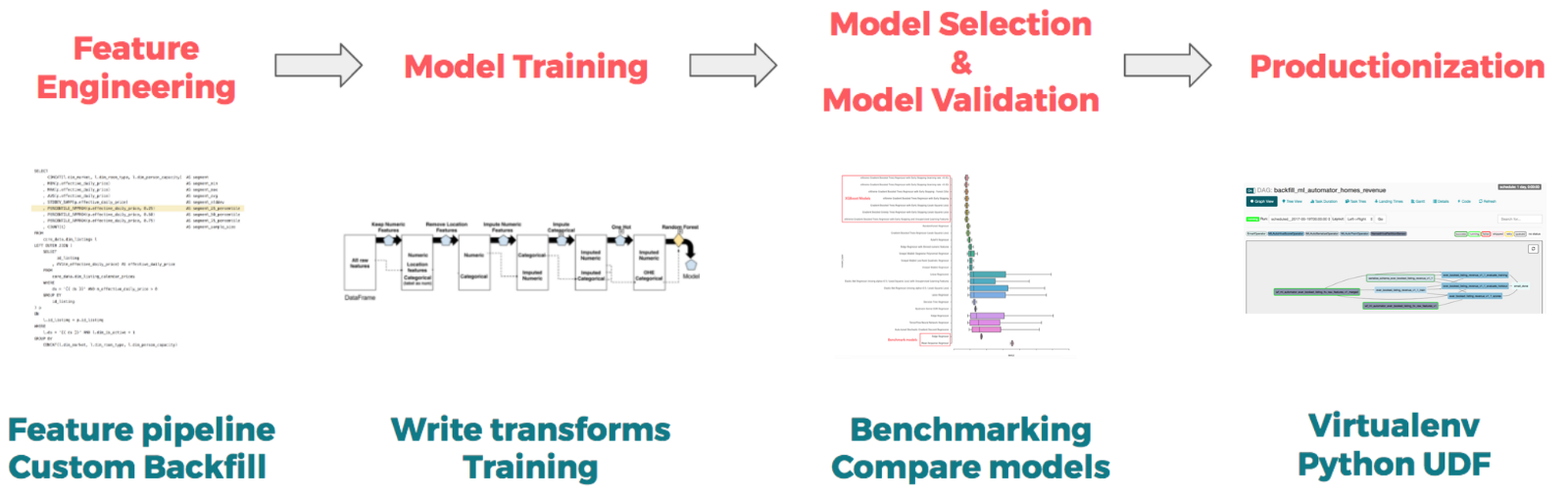
At the Feature Engineering phase, Airbnb used their internal feature repository Zipline, which provides features at different levels of granularity, such as the host, guest, listing, or market level. The crowdsourced nature of this internal tool allows their data scientists to use a wide variety of high quality, vetted features that others have prepared for past projects. If the desired feature is not available, a user can create his/her own feature with a feature configuration file.
At the Prototyping and Training phase, Airbnb constructed data pipelines, available in Scikit-Learn and Spark, that allow their data scientists to specify high-level blueprints that describe how features should be transformed, and which models to train. At a high level, they used pipelines to specify data transformations for different types of features, depending on whether those features are of type binary, categorical, or numeric. The advantage of writing prototypes with pipelines is that it abstracts away tedious data transformations using data transforms. Collectively, these transforms ensure that data will be transformed consistently across training and scoring, which solves a common problem of data transformation inconsistency when translating a prototype into production.
At the Model Selection phase, Airbnb utilized their AutoML frameworks to speed up the process. By exploring a wide variety of models, they found which types of models tended to perform best. For example, they learned that eXtreme gradient boosted trees (XGBoost) significantly outperformed benchmark models such as mean response models, ridge regression models, and single decision trees.
Finally, for Taking Model Prototypes to Production, Airbnb built a framework called ML Automator that automagically translates a Jupyter notebook into an Airflow machine learning pipeline. This framework is designed specifically for data scientists who are already familiar with writing prototypes in Python and want to take their model to production with limited experience in data engineering.
4 - Fighting Financial Fraud
Fighting financial fraud is one of the most important tasks at Airbnb to ensure the trust in their platform. The company has leveraged machine learning, experimentation, and analytics to identify and block fraudsters while minimizing the impact on the overwhelming majority of its good users.

Like all online businesses, Airbnb faces fraudsters who attempt to use stolen credit cards. When the true cardholder realizes their card has been stolen and notices unauthorized charges on their bill, the credit card company issues what’s called a “chargeback,” and the merchant returns the money. Airbnb detects financial fraud in a number of ways, but their workhorse method uses machine-learning (ML) models trained on past examples of confirmed good and confirmed the fraudulent behavior.
To stop the use of stolen credit cards, their chargeback model triggers a number of frictions to ensure that the guest is in fact authorized to use that card, including micro-authorization (placing two small authorizations on the credit card, which the cardholder must identify by logging into their online banking statement), 3-D Secure (which allows credit card companies to directly authenticate cardholders via a password or SMS challenge), and billing-statement verification (requiring the cardholder to upload a copy of the billing statement associated with the card).
5 - Listing Home Recommendations
Very recently, Airbnb has developed a Listing Embedding technique for the purpose of improving Similar Listing Recommendations and Real-Time Personalization in Search Ranking. The embeddings are vector representations of Airbnb homes learned from search sessions that allow them to measure similarities between listings. They effectively encode many listing features, such as location, price, listing type, architecture and listing style, all using only 32 float numbers.

Embedding is a concept from Natural Language Processing used for word representations. Researchers from the Web Search, E-commerce and Marketplace domains have realized that just like one can train word embeddings by treating a sequence of words in a sentence as context, the same can be done for training embeddings of user actions by treating the sequence of user actions as context. Examples include learning representations of items that were clicked or purchased or queries and ads that were clicked. These embeddings have subsequently been leveraged for a variety of recommendations on the Web.
At Airbnb, they trained and optimized their models to learn listing embeddings for 4.5 million active listings on Airbnb using more than 800 million search clicks sessions, resulting in high quality listing representations. To evaluate what characteristics of listings were captured by the embeddings, they examined them in several ways. First, to evaluate if the geographical similarity is encoded, they performed k-means clustering on learned embeddings. Next, they evaluated average cosine similarities between listings of different types (Entire Home, Private Room, Shared Room) and price ranges and confirmed that cosine similarities between listings of the same type and price ranges are much higher compared to similarities between listings of different type and price ranges.
At the time of Airbnb’s testing embeddings, the existing algorithm for their Similar Listings features consisted of calling their main Search Ranking model for the same location as the given listing followed by filtering on same price range and listing type as the given listing. Therefore, their next idea was to leverage embeddings in Search Ranking for real-time in-session personalization, where the aim is to show to the guest more listings that are similar to the ones we think they liked since starting the search session and fewer listings similar to the ones we think they did not like.
Data Science @ Airbnb
Besides from these usages, Data Science, in general, has been heavily invested at Airbnb. From the Knowledge Repo that archives and transfers knowledge across the organization, to Superset that scales data access and visual insights, from the Dataportal which provides valuable resources and tools that address data science issues, to the Automated ML system that can vastly increased a data scientist’s productivity by order(s) of magnitude, data science has been democratized at the individual, team, and organization’s levels. With stable data infrastructure, sophisticated internal tools, and reliable warehouse, Airbnb is undoubtedly one of the best data-driven tech companies that make great use of this technological trends.
I hope this post was informative and tickled your curiosity like it did mine. For now, I’ll be working my way through my upcoming travel plans, finding great locations and reputable hosts, knowing and appreciating all the machine learning that’s going on behind the scenes.
Sources:
- How Airbnb Uses Machine Learning to Detect Host Preferences (Bar Ifrach, Director of Data Science @ Airbnb)
- How We Deliver Insights to Hosts (Deepank Gupta, Engineering Manager & Kidai Kwon, Software Engineer @ Airbnb)
- Using Machine Learning to Predict Value of Homes on Airbnb (Robert Chang, Data Scientist @ Airbnb)
- Fighting Financial Fraud with Targeted Friction (David Press, Trust Data Scientist @ Airbnb)
- Listing Embeddings for Similar Listing Recommendations and Real-Time Personalization in Search (Mihajlo Grbovic, Senior Machine Learning Scientist @ Airbnb)
If you enjoyed this piece, I’d love it if you can share it over social media so others might stumble upon it. You can sign up for my newsletter in the footer section below to receive my newest articles.