
At the end of January, I attended REWORK’s Deep Learning 2.0 Virtual Summit, which brings together the latest technological advancements and practical examples to apply deep learning to solve challenges in business and society. As a previous attendee of their in-person summit, I enjoyed the unique mix of academia and industry, with sessions from deep learning pioneers at the research forefront and deep learning practitioners building real-world applications.
In this long-form blog recap, I will dissect content from the talks that I found most useful from attending the summit. The post consists of 17 talks that are divided into 5 sections:
Enterprise AI
Ethics and Social Responsibility
Deep Learning Landscape
Generative Models
Reinforcement Learning
1 — Enterprise AI
1.1 — Empowering The Workforce at LinkedIn
LinkedIn’s mission is to create economic opportunities for every member of the global workforce. This entails a complex interplay of tasks for different groups of users: the millions of companies searching for candidates and billions of workers looking for ways to further their careers create a complex marketplace between job seekers and hirers that needs to be optimized. The search, recommendation, and standardization problems in hiring also come with a unique, domain-specific set of considerations to maintain high levels of trust in this ecosystem's robustness. Suju Rajan, Senior Director of Enterprise AI at LinkedIn, discussed recent changes in how LinkedIn utilizes supervised deep learning, natural language processing, and other techniques to connect job seekers and hirers, helping both groups find the perfect match.
The diagram above sketches out LinkedIn’s job recommendations stack:
Member profiles are the query, which goes against the indices of all the jobs in the LinkedIn platform.
The candidate selection layer is tuned for maximizing recall.
There are two ranking layers: the first ranking layer removes outliers, and the second ranking layer optimizes precisely for a specific hiring objective (like the probability that a member applies to a job or the probability that a member gets hired to a job).
Then comes the business logic layer showcasing jobs that expire, jobs with negative effects, etc.
Suju focused on the 2nd ranking layer (the red block) in her talk. Over the years, this ranker has evolved from linear models to more complicated GLMix models. More features have been added to these GLMix models, such as career history embedding, job/member embedding, skill downsampling, etc. However, the cost of adding more features is high, as it is difficult to retrain such complex models in production.
Thus, the LinkedIn team's key question is: If they were to design for maximizing impact, what would be their ML design choices?
The first design choice they made is to share modeling components in a common library.
The second design choice is to make those components extensible for product-specific customizations.
Let’s dive deeper into how LinkedIn designs for leverage (illustrated in the diagram above):
In the first stage of the ranker, a shared multi-task model learns representations of members and jobs based on their context. These representations are pre-computed and cached.
Then, the system takes the jobs that members recently interacted with, embeds them into the same shape of the model, and aggregates them into embeddings representing user activities.
Finally, an online ranking model (optimized for this specific task) takes the pre-computed embeddings and combines them with deep representations of online queries and other online features — generating the final ranking of the jobs shown to the users.
Having the layer of shared embeddings made it easier for LinkedIn to onboard new features. A new feature added to the embeddings will be made available for all products at once. As a result, deployment and monitoring efforts will also be easier.
LinkedIn logs different types of activities (titles of the jobs applied in the last month, locations where these jobs came from, etc.) centrally and uses a shared activity log to personalize recommendations in future visits.
In terms of text understanding, LinkedIn has experimented with complicated deep text encoders in both pre-computation and online models. They also moved from ConvNet models to an internal variant of BERT.
These design update for the ML system has accelerated experimentation (more experiments in one quarter than all of the previous calendar year), increased business impact (+10% job saves and +2% hiring metric), and improved member satisfaction (+14% positive feedback on recommendations).
Suju concluded the talk with three key takeaways:
Think Leverage: Grouping closely related applications will ease the monitoring burden and enable shared ML + business knowledge.
Get Familiar with ML Design: It is important to understand different problems that will arise in the ML development process (retraining, feature drift, missing upstream data, etc.), the complexity of maintenance, and the extensibility of your features.
Collect Granular Metrics: There is no single magical metric, so you need to get granular and choose one aligned with your goals. Additionally, user feedback is a luxury, so use them well.
1.2 — Embedding AI in the Enterprise at Google
Peter Grabowski outlined how Google’s Corporate Engineering team uses AI to spur innovation within Google, identified his team's work, and discussed some considerations to keep in mind while employing AI in the enterprise.
Google is using AI to solve various business challenges in support (ticket routing, automatic ticket resolution through knowledge bases, virtual support agents, real-time ticket trends analysis), human resources (suggesting peer reviewers for performance management, recommending courses/mentors/internal roles, optimizing physical spaces), facilities management (device anomaly detection, building automation and optimization, cafeteria demand prediction), and communications (video conferencing fault detection, document classification, information extraction, document similarity, and de-duplication).
Peter Grabowski. Embedding AI in the Enterprise at Google. REWORK Virtual Summit 2021.
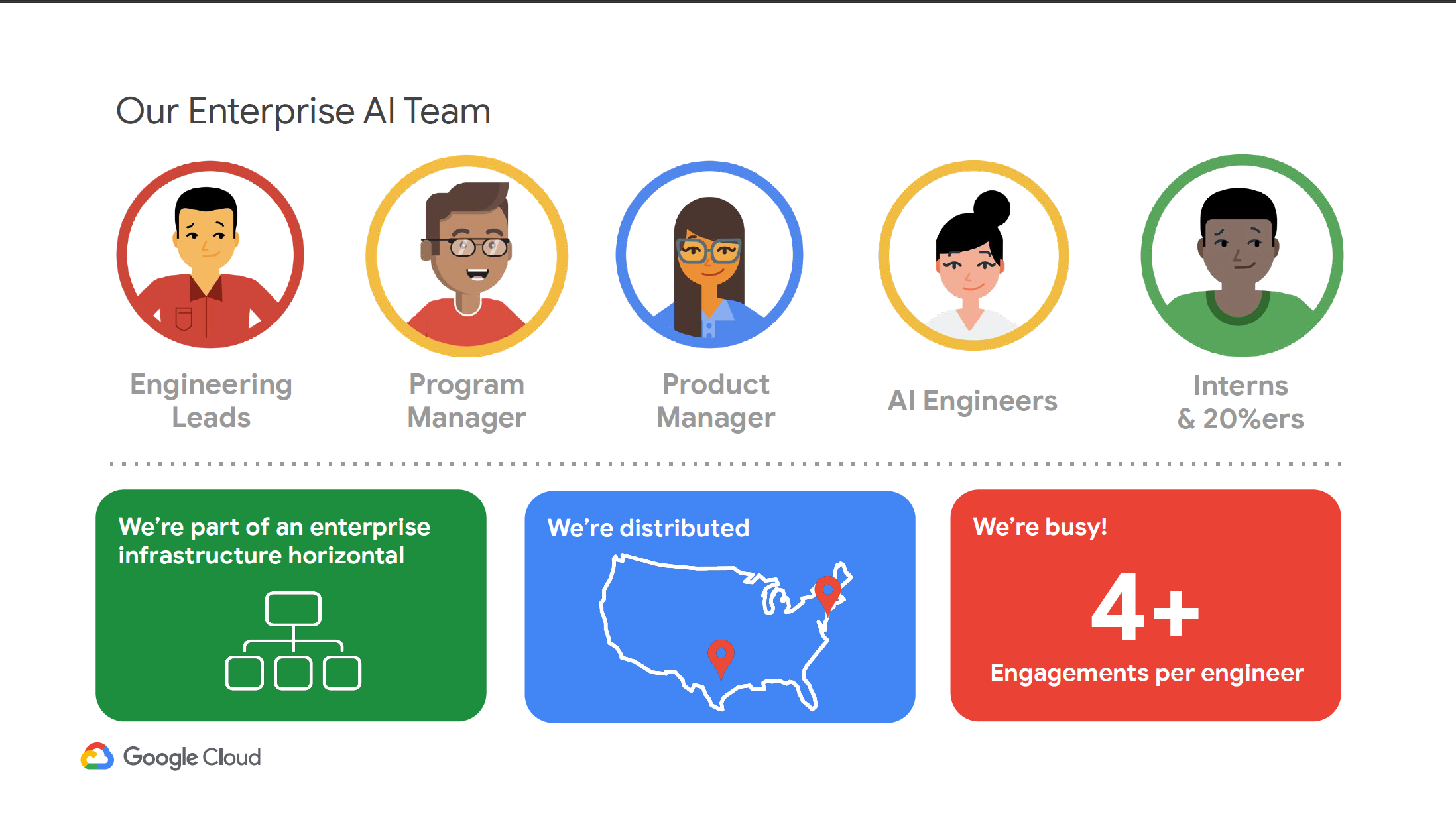
Peter then briefly shared his Enterprise ML team structure, whose mission is to use applied AI as the enterprise competitive advantage. This distributed team is a part of an enterprise infrastructure horizontal and consists of engineering leads, program manager, product manager, AI engineers, interns, and others.
Finally, he briefly walked over the research that’s driving the work his team does and the democratization of AI — including privacy (differential privacy, federated learning, secure computation, remote execution), fairness (many research papers from Google AI), interpretability (such as integrated gradients method), and AutoML (to train custom AI models fast).
1.3 — Building Computational Graphs at DoorDash
Modern ML teams have found great success with combining multiple ML models as ensembles for better predictive performance. However, algorithms implemented in different ML frameworks can’t be serialized into a single combined model for deployment. Arbaz Khan and Hebo Yang shared how DoorDash uses a computational graph approach via a domain-specific language (DSL) to allow teams to use multiple frameworks at once in a single combined model, then demonstrated how this DSL allowed their teams to quickly define and deploy customized models and get high runtime performance during inference.
The talk started with the motivation to use flexible ensemble models.
The DoorDash ML platform team heavily uses rule-based models to tackle many problems due to their predictable behavior and human-readability.
For these models, pre-processing on features could indeed be handled as part of an ETL pipeline and stored in the feature store. However, it is very resource-intensive to precompute and store transformed data for large-scale features, especially for the features requiring exhaustive cartesian products between two features. The platform team would like to support these “feature engineering on-the-fly“ scenarios to increase flexibility and efficient resource usage.
Another use case for ensemble models is having guardrails and post-processing for custom adjustments on model outputs. It is better to support these as part of the model framework instead of having the business applications handle it.
The ML platform needs to support developing and training models with these scenarios inside Python and transforming the processing logic to C++ for each model to ensure that it is fast and scalable in production. However, not only do models from different frameworks each have their own C++ library, but the custom rules and processing steps defined in Python also need to be implemented for each model.
DoorDash ML Platform team has developed an in-house generic solution using a computational graph to handle transformations and models from different frameworks. The user only needs to define a static computation graph with Python DSL and call a helper function to upload to a model store, which serializes the graph in JSON and models in native format. Under the hood, each graph is written in Python DSL, encoded in JSON, and served in C++.
Based on a real-world evaluation scenario on a model that uses 37 features, the platform team confirmed that the custom-built computational graph code significantly reduces the infrastructure cost and boosts model development speed. At the moment, the team is considering integration with open-source frameworks such as TorchScript and Seldon core. Furthermore, they are looking at ways to enable consistency between Python and C++ code and support new functions.
Note: Check out the official post on DoorDash Engineering Blog.
2 — Ethics and Social Responsibility
2.1 — The Challenges of Algorithmic Justice
Deborah Raji from Mozilla gave a succinct talk on algorithmic justice challenges from her experience working with the Algorithmic Justice League, Google’s Ethical AI, Partnership on AI, and NYU’s AI Now Institute. The current widespread use of commercial AI systems necessitates careful attention to bias and abuse. Algorithmic auditing is meant to hold these AI systems accountable, but there are many challenges in engineering such responsibility.
Gender Shades is one such attempt to combat those challenges — an external and multi-target black box audit of commercial ML APIs for the facial analysis task of binary gender classification.
This work advances gender classification benchmarking by introducing a new face dataset composed of 1270 unique individuals that is more phenotypically balanced based on skin type than existing benchmarks.
Additionally, this work introduces the first intersectional demographic and phenotypic evaluation of face-based gender classification accuracy. Instead of evaluating accuracy by gender or skin type alone, accuracy is also examined on 4 intersectional subgroups: darker females, darker males, lighter females, and lighter males.
The findings provide empirical support for increased demographic and phenotypic transparency and accountability in AI systems.
Google’s Model Cards is another work that provides a structured framework for reporting on ML model provenance, usage, and ethics-informed evaluation and gives a detailed overview of a model’s suggested uses and limitations that can benefit developers, regulators, and downstream users alike. It is a part of Partnership on AI’s SMACTR framework for algorithmic auditing that supports AI system development end-to-end, to be applied throughout the internal organization development lifecycle. To get involved with projects like this, you should definitely check out ABOUT ML, an ongoing multi-stakeholder initiative to enable responsible AI by increasing transparency and accountability with machine learning system documentation.
Finally, Deborah proposed using recall as a way to resist technology that doesn’t work for us. A product recall is a process of retrieving defective and/or potentially unsafe goods from consumers while providing those consumers with compensation. Some recalls may result in an item's outright ban, while others may simply ask consumers to return a defective item for replacement or repair. A recall may be voluntary or mandated by a regulatory body.
2.2 — Operationalizing AI Ethics
Alice Xiang from Sony AI discussed some of the steps Sony AI is taking to operationalize AI ethics and some of the key research questions Sony AI will be exploring around fairness, privacy, explainability, and casualty. Given that AI ethics is an area with many competing values and the need for highly contextualized solutions, research will play a key role in bridging the gap between the goals of AI ethics and their operationalization.
Sony’s AI ethics guidelines include these 7 principles: (1) supporting creative lifestyles and building a better society, (2) stakeholder engagement, (3) provision of trusted products and services, (4) privacy protection, (5) respect of fairness, (6) pursuit of transparency, and (7) evolution of AI and ongoing education. These principles are broken down into 3 key areas: fairness, transparency, and accountability.
In the fairness axis, there is the need for more representative/diverse training datasets to measure bias (especially along protected attributes) and to mitigate bias. Many different fairness metrics have been proposed in research, but there is no silver bullet one, and contextual evaluation is needed to pick the right metrics. Two challenging questions about how to measure diversity are: (1) How do you define demographic categories? and (2) What about people who do not fit in specific taxonomies? Alice then brought up two research while at the Partnership on AI: one on the barriers to bias detection (Andrus et al., 2021) and another on the legal restrictions to use (Xiang, 2020).
In the transparency axis, current explainability techniques across the industry are primarily used for debugging by internal ML developers (Bhatt et al., 2020). To make explanations more useful, we need to open the “black box” and increase trustworthiness by providing intuitive/causal explanations to provide stakeholders a better understanding of how the AI system works. Without causal interpretations, it’s easy to learn the wrong inference from data.
In the accountability axis, Sony follows a 3-prong approach: (1) a quality management system that enables collaboration between product units and divisions addressing legal issues, privacy, human rights, etc., (2) an AI ethics assessment framework for its AI products, and (3) tools to help ensure that products are aligned with the policies of the AI ethics guidelines. Two challenging questions about accountability remain: (1) How do we assess the potential societal impacts early in the AI development process? and (2) How do we design guidelines that are flexible enough to deal with diverse contexts but strict enough to be enforceable?
Currently, there is a lack of clear consensus or policies for AI ethics. In highly regulated domains, there are open questions about how existing laws apply to AI. In other domains, there is a lack of guidance around AI in general. With ethics, there are many values to optimize for; thus, much research is needed to navigate such complex tensions and ensure a nuanced, contextualized approach.
3 — Deep Learning Landscape
3.1 — Open-Endedness for AI
While much of AI focuses on solving problems, open-ended processes are arguably far more powerful even though they do not solve any specific problem. Instead, an open-ended process continues to produce increasingly complex yet unpredictable new inventions and innovations forever. Kenneth Stanley from OpenAI argued that open-endedness is possible because humans ourselves are the product of such a process –- evolution –and because we have exhibited open-endedness ourselves over the creative explosion of millennia of civilization. Thus to truly achieve intelligence at the human level, we must ultimately account for open-endedness.
Compared to traditional machine learning techniques, open-endedness is a different kind of learning, in which the goal is not to learn something but to learn everything. It is inspired by natural evolution — the ongoing creation of all the diversity of life on Earth. There is not just a single positive result but an ongoing cacophony of surprises. This open-endedness has been the backbone of human innovation in art, science, architecture, and more. The questions are: Why don’t we create open-ended algorithms? Why do we only solve specific problems?
Because of the inspiration from natural evolution, the study of open-ended algorithms has focused primarily on EAs. However, it is certainly conceivable that a non-evolutionary process (such as an individual neural network generating new ideas) could exhibit open-ended properties. Nevertheless, researchers in this area often refer to it as open-ended evolution (OEE) because of the historical evolutionary focus. OEE is the power of creation that is potentially transformative, leading to boundless creativity on demand and discoveries beyond the scope of optimization. In fact, it may be the path to AI itself.
Kenneth then provided a brief history of open-endedness, covering artificial life research, novelty search algorithm, quality diversity (QD) algorithms, minimal criterion coevolution, and more recently, the Paired Open-Ended Trailblazer projects (POET and Enhanced POET). The main question that POET tackles is: Can we open-endedly invent new problems and optimize solutions to those problems indefinitely?
By combining previous ideas in the field, POET continually optimizes within generated environments and attempt solution transfer between them.
Thanks to its divergence and focus on collecting and leveraging stepping-stones, POET achieves a breadth of skilled behaviors that may be unreachable in any conventional way.
Moreover, POET invents its own challenges instead of requiring humans to create them.
Furthermore, many challenges and the skill sets to solve them are discovered in a single run, instead of relying on the random initializations and idiosyncrasies of different runs to produce interesting diversity.
In principle, with a more sophisticated encoding for the environment space, POET could continue inventing new challenges and their solutions for vast stretches of time, or even indefinitely.
Open-endedness is fascinating not just for its practical benefits in producing solutions to hard problems and the set of skills needed to solve them but also for its propensity for creativity and its ability to surprise us. Kenneth ended the talk with a call to action to focus on open-endedness research that highlights neglected dimensions of intelligence, such as divergence, populations, diversity preservation, stepping stone collection, generating new solutions and new problems/opportunities at the same time, etc.
Note: Check out this O’Reilly piece for a non-technical introduction to open-endedness and this book “Why Greatness Cannot Be Planned: The Myth of the Objective” for more thoughts on divergent search.
3.2 — Continual Learning Quirks and Assumptions
Continual learning is a research direction that has gained an increasing level of interest in the past couple of years, thanks to its capacity to handle the catastrophic forgetting issue. Typically, continual learning approaches are categorized by ways they tackle forgetting, such as regularization-based, memory-based, distillation-based, and parameter-isolation-based. However, they do vary in terms of simplifying the assumptions they encode, so keeping track of these assumptions is extremely important for fair comparisons and also to understand the limitations of each of them. The majority of existing continual learning algorithms focus on one particular setting/small-scale experiments, fail to generalize, and are over-simplified/sensitive to hyper-parameters.
Puneet Dokania of Oxford University and Five AI proposed an approach called GDumb that is free of many of the assumptions mentioned above. GDumb comprises two key components: a greedy balancing sampler and a learner.
The sampler greedily stores samples from the data-stream with the constraint to asymptotically balance class distribution given a memory budget.
It is greedy in the sense that whenever it encounters a new class, the sampler simply creates a new bucket for that class and starts removing samples from the old ones, in particular, from the one with a maximum number of samples.
Any tie is broken randomly, and a sample is also removed randomly, assuming that each sample is equally important.
When tested on various scenarios on which various recent works have proposed highly tuned algorithms, GDumb surprisingly provides state-of-the-art results with large margins in almost all the cases. Puneet concluded that this is alarming as the methods they compared against were specifically designed for the evaluation setting and had hyper-parameters to tune. This raises concerns relating to the popular and widely used assumptions, evaluation metrics and also questions the efficacy of various recently proposed algorithms for continual learning.
3.3 — Open-Domain Question Answering
Question answering (QA) is one of the earliest and core topics in natural language processing and has played a central role in many real-world applications such as search engines and personal assistants. The problem of open-domain QA, which aims to automatically answer questions posed by humans based on a large collection of unstructured documents, has gained popularity in the last couple of years. Danqi Chen from Princeton University reviewed exciting advances in the field and discussed the role of pre-training in QA, learning dense representations for retrieval, and the trade-off between accuracy, storage, and runtime efficiency.
Open-domain QA is the task of answering general domain questions in which the evidence is not given as input to the system. This is in contrast to closed-domain QA that deals with questions under a specific domain. Recent progress in the field owes a big thank to (1) the creation of training datasets and unified benchmarks (TriviaQA, TREC, SQuAD, Natural Questions, WebQuestions); and (2) new modeling ideas, including pre-training and end-to-end training.
A well-known approach to open-domain QA is the retriever-reader framework proposed in the DrQA system using Wikipedia as the unique knowledge source.
This framework consists of two components: a Document Retriever module for finding relevant articles and a Document Reader for extracting answers from a single document or a small collection of documents.
Another great work in this framework is BERTserini, which integrates best practices from information retrieval with a BERT-based reader to identify answers from a large corpus of Wikipedia articles in an end-to-end fashion.
Both DrQA and BERTserini use a sparse retriever, where the text data is represented as weighted term vectors over unigrams/bigrams in questions and passages. These vectors are, unfortunately, not trainable. Can we represent and learn the dense representations for both questions and passages? Dense Passage Retriever is a simple method that tackles this question.
The training scheme leverages a standard BERT pre-trained model and a dual-encoder architecture using only 1,000 question and passage pairs.
The embedding is optimized to maximize the question's inner products and relevant passage vectors, with an objective comparing all pairs of questions and passages in a batch.
Empirical results verify that dense retrieval can outperform and potentially replace the traditional sparse retrieval component in open-domain question answering.
Besides the retriever-reader framework, Danqi also brought up the phrase-retrieval framework that reduces two stages to one stage retrieval.
This idea is initially proposed in the DenSPI system. The phrase module includes a dense representation (start and end vectors from BERT learned from QA datasets and coherency scalar) and a sparse representation (TF-IDF vector for the corresponding document and paragraph vector). DenSPI has extreme runtime efficiency, but underperforms compared to the two-stage framework, depends heavily on its sparse component, and requires large storage.
DensePhrases is an upgraded system that includes learning query-agnostic phrase representations via question generation and distillation, using novel negative-sampling methods for global normalization, and query-side fine-tuning for transfer learning. Empirical results verify that DensePhrases match state-of-the-art retriever-reader models while using only 5% of the training data.
3.4 — Crafting The Next-Generation of AI with AutoNAC
Taking an AI model from the lab to production is extremely challenging. One of the major bottlenecks in the path from the lab to production is algorithmic complexity. Such complexity leads to unsatisfying performance and a long development cycle, making it nearly impossible for commercialization at scale.
Yonatan Geifman from Deci AI looks at the Neural Architecture Search (NAS) line of research, an ambitious algorithmic acceleration technique for aggressive inference speedups. Most common works in this area include NasNet, MnasNet, EfficientNet, and MobileNet-V3.
Deci’s proprietary AutoNAC engine leverages a NAS component that revises a given trained model to optimally speed up its runtime by as much as 10x while preserving the model’s baseline accuracy.
As input, the AutoNAC process receives the customer baseline model, the data used to train this model, and access to the target inference hardware device.
AutoNAC then revises the baseline backbone layers that carry out most of the computation and redesign to be an optimal sub-network.
This optimization is carried out by performing a very efficient predictive search in a large set of candidate architectures.
During this process, AutoNAC probes the target hardware and directly optimizes the runtime, as measured on this specific device.
The final fast architecture is then fine-tuned on the data provided to achieve the same accuracy performance as the baseline. It is then ready for deployment.
Besides the core AutoNAC algorithm, Deci’s inference acceleration stack also includes:
Model Compression: quantization techniques reduce the numerical representation of model weights and activations and can be used to speed up runtime if the underlying hardware supports it.
Runtime: drivers are programmed and tailored for each specific target hardware device, while graph compilers optimize the network graph and then generate optimized code for target hardware.
Inference Hardware: the hardware is designed with parallelism, shared memory size, virtual memory efficacy, and power consumption in mind.
Note: Read this article to see how AutoNAC hits 11.8x inference acceleration at the MLPerf benchmark.
4 — Generative Models
4.1 — Label-Free Bias Mitigation for Fair Generative Modeling
As generative ML applications become more prevalent, it becomes increasingly important to consider questions regarding such systems' potentially discriminatory nature and ways to mitigate it. Biases in the training data are a major factor that contributes to such discriminatory nature. Generative models can easily amplify the bias by generating more biased data at test time. Further, the bias factors of interest are typically latent, easily picked up by the deep generative models.
Aditya Grover from Facebook AI presented FairGen, a weakly-supervised approach to learning fair generative models in the presence of dataset bias. The motivation for using weak supervision is that obtaining multiple unlabelled, biased datasets is relatively cheap for many domains. The goal of FairGen is to learn a generative model that best approximates the desired reference data distribution.
FairGen incorporated an importance weighted objective for data-efficient learning that corrects bias by re-weighting the biased data points. A binary classifier estimates these weights. Based on empirical evaluation on the CelebA dataset, Aditya and his colleagues showed that FairGen outperforms baselines by up to 34.6% on average in reducing dataset bias without incurring a significant reduction in sample quality.
It would be interesting to explore whether even weaker forms of supervision would be possible for this task, e.g., when the biased dataset has a somewhat disjoint but related support from the small, reference dataset — this would be highly reflective of the diverse data sources used for training many current and upcoming large-scale ML systems.
Note: Check out the full paper on arXiv and look at the code repository.
4.2 — Synthetic Data for ML Applications in Healthcare
Machine learning has the potential to catalyze a complete transformation in many domains, including healthcare. However, researchers in this field are still hamstrung by a lack of access to high-quality data, which results from perfectly valid privacy concerns. Mihaela van der Schaar examined how synthetic data techniques could offer a powerful solution to this problem by revolutionizing how we access and interact with various datasets. Her lab is one of a small handful of groups cutting a path through this largely uncharted territory.
ML for healthcare involves a balance between risks and benefits. On the one hand, the information contained in electronic health records is inherently sensitive, and abuse of such information could cause great harm. On the other hand, using electronic health records for entire populations could completely transform healthcare research and delivery, driving life-saving insights and making new and powerful connections that we are currently unable to see. The two main challenges lie in privacy and fidelity:
Privacy: There is no universally accepted and quantifiable definition of privacy exists. The data guardians set the terms for providing data and have all sorts of different requirements. Regulatory efforts (GDPR and HIPAA) do not provide clear definitions, safeguards, or reassurance.
Fidelity: How should synthetic data be evaluated? How do we tell whether a generated dataset faithfully reflects real data? What are the factors that determine the utility of a generated dataset for a specific purpose?
We need a range of concepts, metrics, and assessment methods for data privacy and data fidelity to address these challenges. Data guardians can select “sweet spot” in the risk-benefit balance, where high-quality yet sufficiently private data can be released confidently. Mihaela argued that the key to breaking this data logjam could lie in synthetic data.
An interesting model that Mihaela brought up is the “synthetic data clearinghouse” — a commonly recognized body that handles sensitive data and generates synthetic data:
Real-world datasets would be converted into multiple versions of synthetic datasets, with different versions designed for different privacy requirements or usage cases. Data users would be able to obtain the synthetic data with relatively low barriers to entry.
Data guardians would no longer need to worry about whether or not to trust individual data users. They could ultimately reap the benefits of new healthcare tools developed thanks to the data they provide.
Data users would be spared the exhausting (and often fruitless) process of seeking individual data guardians and earning their trust. Instead, they could choose from a vast array of high-quality and uniformly presented data.
Individuals in the real datasets would know that their own personally identifiable information would not leave the “trust bubble” and could also be offered the freedom of selecting the degree of information to be shared in the real datasets.
Mihaela then presented two novel research from her lab: ADS-GAN and Time-GAN. ADS-GAN performs adversarial training to handle the user-defined risk-benefit tradeoff and improve the quality of (fully) synthetic data while ensuring that no combination of features could readily reveal a patient’s identity.
To address the privacy challenge, ADS-GAN defines an Identifiability Metric, a formal definition of identifiability that fits GDPR requirements -the probability of re-identification given the combination of all data on any individual patient.
ADS-GAN optimizes a conditioning set for each patient to address the fidelity challenge and generates all components based on these.
Time-GAN is an intersection of multiple research strands: GAN-based methods for sequence generation, auto-regressive models for sequence prediction, and time-series representation learning. Most importantly, Time-GAN handles mixed-data settings, where both static and time-series data can be generated simultaneously.
Time-GAN uses unsupervised adversarial loss on both real and synthetic sequences and stepwise supervised loss using original data as supervision. This explicitly encourages the model to capture the stepwise conditional distributions in the data while taking advantage of the fact that there is more information in the training data than simply whether data is real or synthetic. Therefore, the model can expressly learn from the transition dynamics from real sequences.
Time-GAN introduces an embedding network to provide a reversible mapping between features and latent representations, reducing adversarial learning space's high-dimensionality. This capitalizes on the fact that fewer and lower-dimensional factors of variation often drive the temporal dynamics of even complex systems. The supervised loss is minimized by jointly training both embedding and generator networks. The latent space promotes parameter efficiency and is specifically conditioned to facilitate the generator in learning temporal relationships.
Note: Read this article, check out her lab’s publications on synthetic data/privacy-preserving ML, participate in the Hide-and-Seek privacy challenge, and join the ML for Healthcare Community.
4.3 — Small Molecule Drug Discovery using Quantum ML
The existing drug discovery pipeline is a long and expensive process, which can take 5 to 10 years and cost billions of dollars. The problem of searching for new drugs can be framed as the task of navigating unknown chemical space. Generative models such as VAEs, GANs, and RNNS have been adopted to generate many drug candidates. Their objectives are to (1) search exponential large chemical space and (2) generate molecules invariant to the atoms ordering and show high affinity towards the binding site.
Quantum computing can offer unique advantages over classical computing in drug discovery due to its ability to solve computationally intractable problems and simulate complex physics problems. In particular, Quantum GAN can offer several opportunities: (1) strong expressive power of variational quantum circuits, (2) better trainability due to the reduced issue of vanishing gradients, and (3) exponentially large chemical space for navigation. However, quantum GAN is still at its nascent stage due to qubit constraints on noisy quantum computers.
Junde Li and Swaroop Ghosh from Penn State propose a qubit-efficient quantum GAN mechanism with a hybrid generator and classical discriminator for efficiently learning molecule distributions.
Quantum GAN with a hybrid generator (QGAN-HG) is composed of a parameterized quantum circuit to get a feature vector of qubit size dimension and a classical deep neural network to output an atom vector and a bond matrix for the graph representation of drug molecules.
Another patched quantum GAN with a hybrid generator (P-QGAN-HG) is considered the variation of QGAN-HG.
The quantum circuit is formed by concatenating a few quantum sub-circuits.
Their results show that QGAN-HG generates potentially better drug molecular graphs in Frechet distance (FD) scores and drug property scores and achieves high training efficiency by reducing generator architecture complexity. Moreover, QGAN-HG with patched circuits accelerates the standard QGAN-HG training process and avoids deep neural networks' potential gradient vanishing issue.
Note: Check out the full paper on arXiv and look at the code repository.
4.4 — Realistic Cosmetic Virtual Try-On using GANs
The ability of generative models to synthesize realistic images offers new perspectives for cosmetics virtual try-on applications. Robin Kips from L’Oréal Research/Télécom Paris proposed a new formulation for the makeup style transfer task to learn a color controllable makeup style synthesis.
The makeup style transfer task has mostly been framed as the color translation task, which is challenging because color appearance is highly entangled with material properties, which need to be preserved. Previous works have suffered from these limitations: (1) Due to the implicit representation of the makeup extracted from the reference image, it isn't easy to associate the makeup style with an existing cosmetic product. (2) Once the makeup style has been translated, we can’t modify the generated image.
Robin presented Color-Aware GAN (CA-GAN), a generative model that learns to modify the color of objects in an image to an arbitrary target color:
The generator G estimates an image from a source image and a target makeup color.
The discriminator D estimates the makeup color, skin color, and a real/fake classification from the generated image, used to compute the color regression loss L_color, background consistency loss L_bg and adversarial loss L_adv, respectively.
The source image is reconstructed from the generated one using the makeup color as the target. The reconstruction is used to compute the cycle consistency loss L_cycle.
Furthermore, CA-GAN can be trained on unlabeled images using a weakly supervised approach based on a noisy proxy of the attribute of interest.
For the experiment, the author collected a database of 5000 social media images from makeup influencers, which contains a wider variety of skin tones, facial poses, and makeup color, with 1591 shades of 294 different cosmetics products. The results show that CA_GAN can accurately modify makeup color while outperforming conventional makeup style transfer realism models. Since CA-GAN does not require labeled images, it could be directly applied to other object categories for which it is possible to compute pixel color statistics, such as hair, garments, cars, or animals.
Here are the key takeaways from Robin’s presentation:
Realistic and controllable generative models can be trained without labeled data using weak supervision.
Realistic and controllable generative models can be trained without labeled data using weak supervision.
Generative models are good candidates for the future of Augmented Reality technologies.
Note: Check out the full paper on arXiv and watch the CA-GAN demo.
5 — Reinforcement Learning
5.1 — Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design
A central goal of any RL problem is to design the distribution of tasks and environments that can be used to evaluate and train effective policies. However, designing an appropriate distribution of environments is challenging. The real world is complicated, and correctly enumerating all of the edge cases relevant to an application could be impractical or impossible. Even if the RL method developer knew every edge case, specifying this distribution could take a significant amount of time and effort.
To automate this process, Natasha Jaques from Google AI/Berkeley presented a recent NeurIPS 2020 paper that specifies the domain of environments in which the policy should be trained without fully specifying the distribution. This problem of taking the underspecified environment and a policy and producing an interesting distribution of fully specified environments in which that policy can be further trained is called Unsupervised Environment Design (UED).
There are two prior approaches to UED: domain randomization (generating fully specified environments uniformly randomly regardless of the current policy) and minimax adversary (adversarially generating environments to minimize the reward of the current policy). This paper proposes a novel adversarial training technique called PAIRED (protagonist antagonist induced regret environment design):
The protagonist is the primary agent to be trained, while the antagonist is a second agent that constrains the environment-generating adversary. Both agents are initialized and trained together.
This adversary is incentivized to create the easiest possible environment where the protagonist can’t solve.
As the protagonist solves the simple environments, the antagonist generates more complex environments to outperform the protagonist.
Based on the experimental results (compared to the two previous UED approaches), PAIRED agents learn to solve the longest and most complex mazes, thanks to their capability to generate a curriculum of increasing difficulty.
The most interesting part of the talk is when Natasha mentioned the practical application of PAIRED. In a paper under review for ICLR 2021, PAIRED agents were used to navigate real web pages to complete tasks for users automatically. Autonomous web navigation agents that complete tedious digital tasks can significantly improve user experience and systems’ accessibility. Initial approaches involved hand-programming curriculum of easy, medium, and hard sites. This paper proposes the flexible budgeted PAIRED algorithm, which generates a curriculum of increasingly challenging websites out of common design primitives such as navigation bars, product carousels, item decks, web forms, and item carts. The flexible budgeted PAIRED agents can successfully generalize to navigating complex, unseen websites at test time.
Note: Check out the full paper on arXiv and watch the PAIRED demo.
5.2 — Predictability Maximization — Empowerment as an Intelligence Measure
Intelligence is often associated with the ability to optimize the environment for maximizing one’s objectives. In particular, the ability to predictably change the environment — empowerment — is an essential skill that allows agents to achieve many goals efficiently. Shane Gu from Google Brain discussed empowerment from multiple perspectives, including model-based and classic goal-based RL, and relate it to classic and recently-proposed definitions and measures of intelligence.
Empowerment is defined as the mutual information between the agent’s actions and the world's future states (Jung, Polani, & Stone, 2012; Mohammed and Rezende, 2015). Empowerment can be used in the reward function for unsupervised skill discovery (Sharma et al., 2019; Sharma et al., 2020) and to control the degrees of freedoms of the RL system (Wade-Farley et al., 2018; Eysenbach et al., 2018; Hafner et al., 2020).
Shane looked specifically at RL work that uses reward empowerment as a metric for intelligence and task difficulty. There are many RL benchmark tasks, but we do not yet have a practical measure to rank difficulties in these environments. Currently, task difficulty can be defined as (1) how much resource (compute, data, people) it takes to solve a task given fixed intelligence (algorithm); or (2) how much intelligence it takes to solve a task given fixed resource.
Reward empowerment is the mutual information between rewards and policy parameters, used to measure how controllable rewards are through exploring policy parameters. Intuitively, if rewards are easier to control, then they are easier to maximize. One limitation of this design is that this measurement is local to initialization. If the later optimization landscape is drastically different from the early one, reward empowerment may not correlate well with an overall learning difficulty.
Shane ended the talk, concluding that most existing quantitative measures for intelligence lack practical and scalable definitions for tasks, objectives, and reward functions. Empowerment maximizability seems like an intuitive and tractable metric for intelligence. By estimating RL task difficulties via reward empowerment, we can check if we have a more intelligent algorithm or just an easier environment, allowing us to improve an algorithm's intelligence.
5.3 — Safe, Interpretable, and Moral RL
Reinforcement learning is a powerful machine learning paradigm, where agents (like robots) are trained through rewards to perform tasks. While such an approach has proven successful in solving closed-world video games, it isn't easy to apply in the real world. One challenge is to create safe agents, i.e., agents that do not unintentionally damage themselves or the environment. Joel Lehman from OpenAI described the challenges of AI safety and reviewed three research projects aimed at steps towards safer, more interpretable agents and that respect moral rules.
Here are the three challenges towards safe RL that Joel proposed:
Interpretability: How can humans understand an RL agent? This might give us more trust in the agent.
Empathy: Can an RL agent care about and understand other agents? This ensures that the agent might not then unintentionally harm humans.
Morality: Can an RL agent abide by ethics, norms, and laws? This might enable us to deploy RL safely in tricky and unforeseen situations.
On the interpretability front, Joel discussed Uber AI Lab’s paper “An Atari Model Zoo for Analyzing, Visualizing, and Comparing Deep Reinforcement Learning Agents,” — whose goal is to make it easier to research the behavior of RL agents produced by different algorithms.
To make it easier for researchers to conduct this sort of science, they ran a selection of common deep RL algorithms at scale across Atari Learning Environment games to create and release a collection of pre-trained models: an Atari model zoo.
In addition to releasing the raw data of trained models, they also open-sourced software that quickly analyzes them. This software enables comparing and visualizing trained agents produced by different deep RL algorithms.
While the main reason we created the zoo was to encourage research into understanding deep RL, the trained models may also be useful for transfer learning research (e.g., to explore how to successfully leverage training on one game to more quickly learn to play another one), and the data the models generate could be used to explore learning or using models of Atari games for model-based RL.
On the empathy front, Joel discussed the paper “Towards Empathic Deep Q-Learning.”
All RL algorithms require a reward function that gives rewards to agents for doing something right. It is easy to make a reward function that recognizes accomplishing a goal, but hard to make a reward function that characterizes all possible negative effects agent might have on the environment.
This paper introduces an extension to Deep Q-Networks (DQNs), called Empathic DQN, that is loosely inspired both by empathy and the golden rule (“Do unto others as you would have them do unto you”). If the agent sees another agent in the training environment, it tries to imagine (1) switching place with the other agent, (2) contemplating what value it would give that situation, and (3) maximizing not only its own reward but a weighted sum of its own reward and the combined imagined reward. Furthermore, the agent can adjust “selfishness” by weighing its own reward versus the other’s reward.
Proof-of-concept results in two grid-world environments highlight the approach’s potential to decrease collateral harms. However, many research directions remain: How to robustly identify other agents in the environment? How to imagine the world from their perspective? How to learn what they value (“inverse reinforcement learning”)? How to balance achieving your goals with respecting their values?
On the morality front, Joel discussed his latest work, “Reinforcement Learning Under Moral Uncertainty” (code):
Motivated by the need for machines capable of handling decisions with moral weight, this work attempts to bridge recent work in moral philosophy on moral uncertainty with the field of RL. We want RL agents to behave ethically, but there are many ethical theories out there, and there is no widespread agreement even among philosophers. Therefore, the agents should perhaps take into account their uncertainty about ethics.
Motivated by the principle of proportional say (which says that without a common scale, the “influence” of a theory should be proportional to its credence), the author decided that voting is the best way to make decisions under moral uncertainty. The particular voting system will depend on the specific definition of Proportional Say and what “influence” means.
The paper resorts to Nash voting, inspired by game theory and has Nash equilibria as its solution concept. In Nash voting, a voting agent is associated with each theory, which outputs a set of votes at each step. Voting agents are trained to optimize choice-worthiness for the theory they represent. The overall agent takes action with the most votes.
Using grid-world environments based on moral dilemmas common in moral philosophy, the authors conducted experiments and introduced algorithms that can balance optimizing reward functions with incomparable scales and show their behavior on sequential decision versions of moral dilemmas.
The overarching goal highlights the important under-studied machine ethics problem and explores its exciting intersection with modern machine learning.
5.4 — The AI Economist
Designing sound economic policy is problematic in practice, given a lack of high-quality economic data and limited opportunity to experiment. As an attempt to bridge these gaps, Stephan Zheng from Salesforce Research presented the AI Economist — a two-level deep RL framework to learn economic policy in economic simulations with agents and a planner who both learn and co-adapt.
This research's primary motivation is that income inequality accelerates globally and has been a key social/economic concern. Tax policy provides governments with an important tool to reduce inequality, supporting the redistribution of wealth through government-provided services and benefits. And yet, finding the optimal tax policy is challenging. The primary reason is that while more taxation can improve equality, taxation can also discourage people from working, leading to lower productivity.
Optimally balancing equality and productivity has not been solved for general economic settings, even when the policy objectives can be agreed upon. Part of the challenge is that it is hard to experiment with real-world tax policies. In the place of experimentation, economic theory often relies on simplifying assumptions that are hard to validate, for example, about people’s sensitivity to taxes. Tax systems that have been proposed range from no taxes at all (“free market”), to progressive and regressive tax systems (reflecting whether the tax rate increases or decreases as income increases), to total redistribution.
The AI Economist is the first RL tool for tax policy design.
It is trained on a principled economic simulation that features competitive pressures, trade, and resource scarcity, using AI agents that learn optimal behaviors.
This use of simulation enables the testing of economic policies at a large-scale, including the ability to measure a range of different metrics.
The simulation framework can also be used to speed up experiments with existing proposals for tax systems, validating assumptions and offering the ability to test ideas that come from economic theory.
Learning optimal taxes in a dynamic economy is framed as a two-level, inner-outer reinforcement learning problem.
RL agents gain experience in the inner loop by performing labor, receiving income, paying taxes, and learning by balancing exploration and exploitation to adapt their behavior to maximize their utility.
In the outer loop, the social planner adapts tax policies to optimize its social objective.
The AI Economist learns a tax policy based only on observable data and without knowledge of the skill or utility functions of workers or prior assumptions about the behavior of workers and can be used to optimize for any desired social outcome.
The results show that the AI-driven tax policy can improve the trade-off between equality and productivity by 16% compared to the prominent Saez tax framework. Moreover, the AI agents can learn tax-avoidance behaviors, modulating their incomes across tax periods. The tax schedule generated by the AI Economist performs well despite this kind of strategic behavior.
Overall, research that intersects economics and AI presents a host of new opportunities and challenges:
To develop any new tool for economics and policymaking, we need to build realistic simulations with real-world data, encode social values into reward functions, and transfer AI policies to the real world.
To develop any AI tools for social welfare, we need to design the core RL methodology, address the reality gap robustness, and explain AI policies to relevant stakeholders.
Note: Check out the full paper on arXiv, review the GitHub codebase, and join this Slack community if you are interested in extending this framework and discussing ML for economics.
That’s the end of this long recap. Follow the REWORK website for their events in 2021! Let me know if any of the particular talk content stands out to you. My future articles will continue covering lessons learned from future conferences/summits in 2021 :)



