Back in May, I attended apply(), Tecton’s second annual virtual event for data and ML teams to discuss the practical data engineering challenges faced when building ML for the real world. There were talks on best practice development patterns, tools of choice, and emerging architectures to successfully build and manage production ML applications.
This long-form article dissects content from 14 sessions and lightning talks that I found most useful from attending apply(). These talks cover 3 major areas: industry trends, production use cases, and open-source libraries. Let’s dive in!
Industry Trends
1 — Managing the Flywheel of ML Data
The ML Engineer’s life has become significantly easier over the past few years, but ML projects are still too tedious and complex. Feature stores have recently emerged as an important product category within the MLOps ecosystem. They solve part of the data problem for ML by automating feature processing and serving.
But feature stores are not enough. Data teams need a platform that automates the complete lifecycle of ML features. This platform must provide integrations with the modern DevOps and data ecosystems, including the Modern Data Stack. It should provide excellent support for advanced use cases like Recommender Systems and Fraud. Furthermore, it should automate the data feedback loop, abstracting away tasks like data logging and training dataset generation. Mike Del Balso(Co-Founder and CEO of Tecton) covered his vision for the evolution of the feature store into this complete feature platform for ML.
There are several different stages in the life cycle of ML projects.
Ideation: We come up with the ideas we want to build and design experiments.
Development: We train models and run experiments.
Productionization: We deploy models, put them into production, and serve them live.
Operation: We do not make one set of predictions, as we must maintain them in production.
Mike believes that productionization and operation are stages where we face real challenges. He argued that the ML flywheel is a useful mental framework to keep in mind while developing ML applications to make the productionization and operation stages much easier.
There are two major teams involved in the process of developing ML applications:
The “ML Product” teams are responsible for building the end ML application in production. These teams include ML engineers, data scientists, and product engineers. They reuse whatever is provided to them by the data and infrastructure teams. Think about the fraud team, the recommendation team, the pricing team, etc.
When a company has a variety of ML product teams, the “ML Platform” team is formed to support these ML product teams. The ML platform team implements a reliable and repeatable decision API that’s accurate for the ML product teams. They centralize engineering efforts duplicated across ML product teams by providing them reusable components (training system, serving system, etc.) so that the product teams can then focus on data science and product-specific challenges.
How do we reliably and repeatedly make accurate decisions? That is the key challenge here, and that is what all of MLOps is about.
Repeated accurate decision-making requires a feedback loop: We do something in the real world. We observe how it went. Then we make a decision, act, and observe how it went again. We combine that information with all the other information we know. We update our learnings, we update our model, and then we make another decision.
Every ML application requires a feedback loop as well:
Collect: Given your product usage, you use various tools to log and monitor what is happening to the customers.
Organize: Now, you want to organize these logs and turn them into model datasets.
Learn: You start extracting features, building new models, and updating models.
Decide: Finally, you perform online computations to deliver real-time model predictions and update the product to make new decisions.
This loop is extremely important to understand, as that is how training datasets are generated and predictions are made and delivered to the product.
Great ML applications require great ML flywheels.
When the flywheel is working, ML feels natural and easy. You have a very clear ownership and agency across the whole ML lifecycle. The whole ML application becomes much more debuggable and reliable. Because you know who owns each part of the flywheel, it becomes much easier to move fast, make decisions, make changes, and understand the implications of all these decisions. This allows your iteration speed to be much higher, meaning that your models are getting better and more accurate.
When the flywheel is not working, things go slower and break more. The iteration speed becomes much slower. Because there are unclear owners for each stage (especially in the bottom half of the loop), it is really hard to make changes. Small changes become big tasks, as coordinating across a number of unknown people is challenging. It is hard to promise a certain level of reliability.
We need an easy way for all stakeholders to build and orchestrate ML and data tools into coherent ML flywheels. This requires simple abstractions to define an ML flywheel and manage its infrastructure and artifacts that fit in naturally with best-practice engineering workflows.
Data flows are at the core of the ML flywheel:
Given your product, you make predictions in the product and log a variety of things such as observed metrics, logged predictions and features, and logged labels.
Then you combine all those datasets into feature logs, prediction logs, and labeled datasets.
And then, when building a model, you extract new features and generate new training datasets.
When making predictions, you could be scoring multiple candidates, generating a variety of candidates, extracting features for all of them, scoring them, and turning them into predictions.
Feature platforms have greatly impacted the data flows at the top of the flywheel. They have made it easy to manage the datasets declaratively, define the dataflows that happen in the learn-and-decide stage, and manage all the infrastructure and datasets throughout those stages.
In particular, Tecton creates production-ready feature pipelines from simple declarative definitions. As seen above, on the left side is a simple Python file to define some metadata. Tecton takes that Python file and converts it to a physical implementation — spinning up the right infrastructure, setting up the right data schema, and connecting different pieces together. Tecton also orchestrates the data flows on that infrastructure, backfills your features into your offline feature store (so they can be pulled for training datasets), and loads up the most recent features into the online feature store (so they can serve your models at scale in real-time). In other words, Tecton manages the whole infrastructure and its artifacts end-to-end.
How do we bring these data management patterns to the whole ML Flywheel? Mike recommended three specific strategies:
Close the loop: This means automating and managing the bottom half of the flywheel. Ultimately, you want some log observation API that makes it easy to capture observed events (e.g., labels, features) back into your ML application. Additionally, the entire loop should be implemented using your cloud data platform (Databricks, Snowflake, etc.), so you do not want to spin up a whole new data stack to support the bottom half.
Establish a unified data model throughout your ML flywheel: This goes from user observations to feature generations to model predictions. Data schemas should be generated and maintained automatically across all stages of the loop. Observed events should be automatically propagated to all relevant features, labels, training datasets, models, and predictions, thereby keeping them fresh.
Support use-case-specific architectures: There is no one-size-fits-all since not every use case needs the same underlying infrastructure. For example, batch lead scoring is implemented completely differently from real-time recommendations. Infrastructure has to be optimized for the use case, or else you risk building inefficient, expensive, or not performant solutions.
Tecton is helping teams build their ML Flywheels via unified management of the data lifecycle for the ML applications. This means simple declarative definitions become managed infrastructure and managed datasets throughout the flywheel. They have use-case optimized architectures that are implemented on your data stack and can integrate with your development team’s workflows.
Overall, optimizing the ML flywheel makes everyone’s lives easier. Platform teams can support many more product teams with fewer resources. Product teams can iterate, build, and deploy faster with less glue code, fewer mistakes, less maintenance, more reliability, and fewer people needed per project. This gets you much closer to the mythical decision API. The ML Flywheel is relevant to many use cases (fraud detection, pricing, recommendations, etc.), so you should think about it early and figure out how it maps to your organization!
2 — Lakehouse: A New Class of Platforms for Data and AI Workloads
Many data and ML engineering problems stem from today’s complex data architectures involving multiple systems. Because of this, new “lakehouse” systems help reduce this complexity by supporting data engineering, SQL data warehousing, and ML on the same datastore.
Matei Zaharia (Co-Founder and CTO of Databricks) presented the role of the Lakehouse as an open data platform for operational ML use cases. He discussed the ecosystem of data tooling commonly used to support ML use cases on the Lakehouse, including Delta Lake, Apache Hudi, and feature stores like Feast and Tecton.
The biggest challenges for data users today are data quality and timeliness. If you do not have high-quality data going into your application, whether simple analytics or ML, then you cannot do anything with it. If it takes forever to get the new data for you to look at, then it is a problem. Matei argued that getting high-quality, timely data is hard, but it is partly a problem of our own making for historical reasons.
In the 1980s, with data warehouses, companies had operational databases optimized for analytics over large amounts of historical data. You would take your operational data stores, perform ETL, and load the post-processed into your warehouse. Your warehouse is a full SQL database with rich management and performance features for SQL analytics, such as schemas, indexes, transactions, multi-version control, etc.
In the 2010s, some new problems emerged for the data warehouses. First, data warehouses were SQL and table-centric, so they could not support rapidly growing unstructured and semi-structured data (time series, logs, images, documents, etc.). Secondly, there was a high cost to store large datasets because warehouses were designed for historical and small-scale data (compared to what we have today). Thirdly, because the only interface was SQL, warehouses could not easily support data science and ML.
As a result, we got a new type of system called a Data Lake. This is basically low-cost storage to hold all raw data with a generic file API (e.g., S3, HDFS for on-premise, or Azure Data Lake Storage for cloud storage). With data lakes, it is easy to upload your data (whatever format and type it is), store it there, and build applications downstream from it. Additionally, data lakes came out of the open-source and were designed around open data formats (e.g., Parquet), meaning that the data is accessible directly by the data engineers. However, data lakes have limited management features, so you still need to write ETL jobs that load specific data into other systems for more powerful management and performance features.
Even though data lakes provide low-cost, cheap storage tiers, they are complex to use. A few different problems happen.
Data reliability suffers: You have multiple storage systems with different semantics and many ETL jobs to move data between them.
Timeliness suffers: You have extra ETL steps to get the data in the data lake before data becomes usable in the data warehouse.
The cost is high: You have duplicated data and extra pipelines to deal with.
That is where the lakehouse systems come in. The idea is to implement data warehouse management and performance features on top of directly-accessible data in open formats. It looks like the diagram above: You have the data lake storage at the bottom, something like Amazon S3. On top of it, you have the management and performance layer that gives callers for higher-level abstractions (like transactions or versioning). On top of this layer lie a few interfaces such as BI, reports, data science, and machine learning.
This diagram looks nice, but can we actually get great performance and governance with this design? Matei brought up three areas that are enabling this lakehouse paradigm to work:
Metadata layers on data lakes that add transactions, governance, and other management features
Lakehouse engine designs for performant SQL on data lake storage
Declarative I/O interfaces for ML that can take advantage of these optimizations
Metadata layers on data lakes sit on top of your raw files that try to provide richer semantics. Examples include Delta Lake from Databricks, Apache Iceberg from Netflix, and Apache Hudi from Uber. Basically, you have a collection of files and build the higher-level interface to track which files are part of a table version or a dataset to implement rich management features like transactions. Clients can then access the underlying files at high speed.
For instance, Delta Lake users can track which files are part of each version of the table. Clients can always read a consistent table version, so you can have concurrent users and workloads and do all kinds of management operations on your data directly in the data lake. Additionally, there are other management features such as time travel to old table versions, zero-copy CLONE by forking the log, DESCRIBE HISTORY, streaming I/O (get a stream of changes to a table to use it as a message bus), etc. Thousands of companies have used Delta Lake to manage exabytes of data. There is also broad industry support with all these tools seen below that can integrate with it.
Even though we made data lakes better in terms of management, it is not enough to replace the separate systems we have today. A core issue people worry about is performance. Can you get performant SQL on data lakes? It turns out that today’s open-source column formats are evolving to meet new needs over time. Furthermore, you can use the lakehouse design to implement the following optimizations that improve performance:
You can keep auxiliary data structures like statistics and indexes that are updated with each transaction, so they are always consistent.
You can organize the data within each file.
You can reorder the data to minimize I/O.
You can do caching and design the engine like a data warehouse engine.
These optimizations help with cold and hot data — minimizing the number of bytes you have to scan and performing tasks in memory or the CPU to make the execution faster. New query engines such as Databricks Photons use these ideas in practice.
Finally, lakehouse provides declarative I/O interfaces for ML.
ML over a data warehouse is painful: You have the challenge of setting up reliable data pipelines. This is hard because, unlike SQL workloads, ML workloads need to process large amounts of data with non-SQL code (SQL over JDBC/ODBC is too slow for this at scale). If you decide not to read directly from the warehouse, you can export the data to a data lake, adding a third ETL step that could break your ML pipeline. You can also maintain production datasets in both the data warehouse and the data lake, but that is even more complex, and more things can go wrong as you try to run this application.
ML over a lakehouse is seamless: You gain direct access to data files without overloading the SQL front end by having a single storage tier. The ML frameworks already support reading Parquet files directly from cloud storage without having some other node in between that translates them into a different format. You can also use declarative APIs such as Spark DataFrames to optimize queries further. Additionally, you get built-in features such as data versioning, streaming, and so on to help with the ML lifecycle. For example, you can automatically track which version of a table is used in an experiment with MLflow to get back the same data.
Lakehouse systems integrate with leading ML platforms like Feast, Tecton, and MLflow. This is an exciting area since having such a powerful data management system is important for ML. Historically, we have built different data stores for different workloads. Nowadays, there are fewer technical reasons we would need that in the cloud. The lakehouse paradigm combines the best of data warehouses and data lakes with open interfaces for access from many tools, management features like transactions, high performance via new engines, and low cost equal to cloud storage.
3 — Machine Learning Platform for Online Prediction
A trend in recent years is that the industry is moving toward online predictions and continual learning. A common denominator for both of them is that they both require good monitoring solutions. Chip Huyen (Co-Founder and CEO of Claypot AI) broke down stage-by-stage requirements and challenges for online prediction. She also discussed key design decisions a company might face when building or adopting a machine learning platform for online prediction use cases.
While batch predictions are computed periodically before requests arrive, online predictions are computed on-demand after requests arrive.
Batch predictions are not adaptive because they are computed before the request arrives, so you cannot take into account relevant information to make relevant predictions (as shown a lot in tasks like recommender systems or dynamic pricing). Another problem with batch predictions is the cost. Whenever you generate batch predictions, you tend to generate predictions for all the possible requests.
The big challenge with online predictions is the latency because predictions are computed after request. You would need a machine learning model that can quickly return prediction requests because users do not like waiting.
The workflow for batch predictions looks like the above:
You can generate predictions offline in batch and store them in a data warehouse (Snowflake, BigQuery, or S3).
Many companies load these pre-computed predictions into a key-value store (like DynamoDB or Redis) to reduce the latency at prediction time.
When prediction requests arrive, the key-value store will fetch the pre-computed predictions into the prediction service.
Batch predictions work well for many use cases ranging from churn prediction to user lifetime value prediction. You only need to generate these predictions once a month or once a week.
There are two different types of online predictions. The one seen above is the workflow for online prediction with batch features — features that are computed offline (e.g., product embeddings). For example, in a recommendation system use case, you might want to look into all the products a user has seen in the last half hour and get the embeddings for these items. Then you add them together, create a feature embedding, and generate the recommended items based on these pre-computed embeddings. The embeddings are usually computed beforehand and loaded into a key-value store, thereby reducing the latency at prediction time.
Another level of online prediction deals with online features. For example, in the trending products use case, you want to look into the number of views that all products have in the last 30 minutes. To compute the number of views a product has in the last 30 minutes, you want to compute those features online.
You compute batch features offline and load them into a key-value store.
At prediction time, you look into what online features are needed for the prospect request. If it is a batch feature, you fetch it from the key-value store. If it is an online feature, you can compute them using stream processing or a microservice using a Lambda function.
The problem with the Lamda microservice is that it is stateless. Therefore, you would need to set up an external database to store the data of the computations. A much more efficient way could be to use stream computation engines such as Apache Flink.
As observed in the three diagrams above, the critical difference between them is the feature service (or known as the feature store). A feature store needs certain properties:
Connecting to different data sources, both offline / batch (Snowflake, BigQuery) and streaming (Kafka, Kinesis).
Storing feature definitions in a SQL query or a Pandas data frame.
Performing feature computations: Modern feature stores are light on this aspect, especially on the streaming part, since they tend to leverage Spark Streaming (which derives from Databricks’ batch computation background). Luckily, exciting tools have allowed us to do stream computations efficiently, such as Redpanda, Materialize, and Decodable.
Persisting computed features to reuse them for the next prediction request. Sometimes, different prediction requests might want to access the same feature, or different models might want to have the same features. In this scenario, the feature store is like a data mart.
Ensuring consistency between training and serving for predictions. For batch predictions, you can use the same batch pipeline for batch features in serving and training. For online predictions, this gets trickier. You might want to use streamed computations to get the features, but when training for the same features, you might want to use a batch process. This is a difficult challenge for modern feature stores. If you compute the training features in the feature store, then it can reuse the same feature definitions and go back in time to generate historical features. But if you compute the training features outside the feature store, then it can be hard to ensure this consistency.
Monitoring features: The last aspect of the feature store functionality is to ensure that every feature generated in the feature store will be usable and correct (or within certain expectations). With batch predictions, you can write many tests to do so. But for online predictions, you need a way to ensure that nothing in your pipeline breaks, leading to the wrong online features.
Chip then dissected the concept of monitoring. The first question you need to address is what to monitor. Companies care about business metrics such as accuracy, CTR, etc. However, it is hard to monitor the business metrics directly because you need a lot of labels or feedback from users, and not every task has labels or feedback from users immediately that you can use to monitor the models. To get around these issues, companies try to collect as much feedback as possible (click, add to cart, purchase, return, etc.) and look for fine-grained, slice-based evaluations (per class, per tag). Because of the lack of labels and predictions, many monitoring tools turn to monitor proxies, assuming that a shift in prediction and feature distribution will also lead to decreased business metrics. In this case, monitoring becomes a problem in detecting distribution shifts.
That leads us to the following question: How do we determine that two distributions are different? The base distribution we compare to the other distribution is called the source distribution, and the distribution that we care about seeing whether it has deviated from the source is called the target distribution. There are two main approaches to detecting shifts:
Comparing statistics: You compare certain statistics of the source distribution (mean, variance, min-max) with the target distribution and observe any divergences. The problems with this approach are that it is distribution-dependent and inconclusive.
Using two-sample hypothesis tests: The vast majority of hypothesis tests can only work with low-dimensional data and generally do not work with high-dimensional data (like embeddings). Thus, people usually perform dimensionality reduction on high-dimensional data before applying hypothesis testing.
When talking about shift detection, it is important to note that not all shifts are equal, as some are easier to detect than others.
Sudden shifts are easier to detect than gradual shifts. If you were comparing the data today to yesterday, you might not see many changes and think there is no shift. But over time, because the shifts are gradual, you might not be able to check them after a week.
Spatial shifts are easier to detect than temporal shifts. Spatial shifts happen with any new access point, like new devices or new users. On the other hand, temporal shifts happen with the same users or same devices, but behaviors have changed over time. For temporal shifts, the time window scale matters a lot — choosing a too-short window leads to false alarms of shift, while choosing a too-long window might take too long to detect shifts. Many stream processing tools allow you to merge shorter time scale windows into larger time scale windows. Others can perform root-cause analysis by automatically analyzing various window sizes to have you determine the exact point in time where the shift happens.
As mentioned above, the two proxies companies use to monitor their ML systems when they do not have enough labels and feedbacks are predictions and features.
Since predictions are low-dimensional, it is easy to visualize, compute statistics, and do two-sample tests on them. Changes in prediction distribution generally mean changes in the input distribution. However, a prediction distribution shift can also be caused by a canary rollout (a new model slowly replaces an existing model). If your new model produces significantly different predictions from your existing model, there might be some problem with the new model, and you should look into it.
Monitoring features is a lot harder and more complex. For a given feature, you might want to monitor changes in a feature’s statistics by generating expected statistics or schemas of that feature from the source distribution and monitoring the mean and variance of that feature’s input actions during training. If it changes, then the distribution of that feature has shifted. The challenges here include compute and memory cost (computing statistics for 10,000s of features is costly), alerting fatigue (since most expectation violations are benign), and schema management (as feature statistics and schema changes over time, you need to find a way to map features to the schema version).
The vast majority of monitoring solutions nowadays focus on feature monitoring. So do feature stores since they are already computing and persisting feature values, which could be a natural place to do the monitoring. Chip hypothesized that there would be some convergence between monitoring solutions and feature stores moving forward.
4 — How to Build Effective Machine Learning Stacks
Although hundreds of new MLOps products have emerged in the past few years, data scientists and ML engineers still struggle to develop, deploy, and maintain models and systems. In fact, iteration speeds for ML teams may be slowing! Sarah Catanzaro (a General Partner at Amplify Partners) discussed a dominant design for the ML stack, considered why this design inhibits effective model lifecycle management, and identified opportunities to resolve the key challenges that ML practitioners face.
It is hard to understand how components of the ML stack fit together. Even if you have some ideas about how they should fit together, it can still be tough to implement. Sarah argued that we need a common language to describe the key components of the ML stack and how they inter-relate.
There are three different layers, as seen above:
The data management layer focuses on tools and platforms that will enable you to collect, query, and evaluate training datasets, labels, and predictions.
The modeling and deployment layer includes tools to build, train, tune, optimize, and deploy models.
The model operations layer enables users to either meet or exceed their performance requirements and conform with regulatory or policy standards.
Double-clicking on the data management layer:
Data labeling tools enable users to label data by (1) access to tools that manage human labelers or (2) programmatic techniques like weak supervision. There are also more tools that focus on enabling users to evaluate and improve label quality.
Databases tools collect and query labels, training datasets, and predictions. There are a couple of approaches here: Data warehouses are optimized for structured data and commonly used by analytics teams. ML teams can cut down time on data preparation by using the data models that analytics engineers have prepared (which are monitored, tested, and well-documented). The other approach is to build an ML stack on top of the data lake, which is optimized for storing and managing raw data (both structured and unstructured). Data lakes tend to provide a better Python-native experience. The last approach entails using vector databases that are becoming more common for applications that rely upon embeddings.
Feature management (with feature stores as the predominant category) tools enable you to transform data into features that can be used reliably during training and inference. They also solve gnarlier technical problems such as backfilling or resolving online-offline inconsistencies. Besides feature stores, some companies just use a feature proxy to enable low-latency feature serving.
Zooming in the modeling and deployment layer:
Deep learning frameworks help users build and train models, whereas data science frameworks help users create data science projects. The latter enables you to run and log ML pipelines (i.e., DAGs and workflows) more uniformly.
Some data science frameworks also provide lightweight experiment tracking and version control capabilities. Companies that iterate on their models frequently may choose to adopt experiment tracking applications that are purpose-built for that use case. Often, it will include more robust visualization capabilities and make it easier to reproduce, package, and share models.
Deployment and optimization tools enable users to deploy models as prediction services (usually containerized). Some newer deployment tools are designed to run on the data warehouse and provide optimization capabilities (so you can achieve certain production goals such as low latency, memory requirements, etc.).
Distributed training tools accelerate training typically by leveraging parallel processing.
Lastly comes the model operations layer:
Model monitoring tools are focused on enabling users to detect distribution shifts and detect the root cause of the issues.
Model analytics is a new category that lets ML engineering teams constantly iterate on ML-driven features (think Mixpanel or Amplitude for ML-powered products).
Model compliance tools ensure that protected attributes are not used to make predictions and help users mitigate algorithmic risks.
Continuous learning tools let users automate retraining or enable active learning.
Sarah then went over various anti-patterns when the components above do not work so well together. The first one arises when the components of the data management layer do not connect clearly together. This is going to be more acute as more companies start adopting the data-driven programming paradigm, where they iterate on their datasets to improve model performance.
When you have data stored across multiple systems that are poorly integrated, it will be much harder to find, access, and evaluate datasets. Some companies resolve this problem by tasking data/ML engineers with making data available to data scientists (or whoever is building the model). But then you have these engineers spending all their time just moving data to and from S3 buckets.
There is a lot of duplicate work being done across ML teams and the entire organization — where the data preparation and feature engineering work cannot be easily repurposed.
Finally, there is the challenge of working with unstructured data. There should be tools that let you link your structured data with your unstructured data, so you can easily develop a profile of what might be contained within your unstructured datasets.
The second anti-pattern occurs when the components of the modeling and deployment layer are not elegantly integrated.
The most obvious example is the problem of going from notebooks into production. Most data scientists start the model development process with a deep/machine learning framework in a notebook. But when they are ready to operationalize their work, they often restructure their data as a DAG. At a minimum, that is very tedious to go through their notebook code and extract the DAG.
More advanced ML teams do not treat modeling and deployment as discreet and sequential stages. This behavior makes communication and interaction between data scientists and ML engineers much easier. But many of the tools that have been adopted today do not align with this pattern of working.
The third anti-pattern shows up when the data management and modeling/deployment layers are not coupled.
Most teams will train their models offline in a batch setting. This can be a difficult challenge with finding/accessing the data and reasoning about data freshness and the impact on model performance. Still, batch runtime is easier than online runtime.
Things get gnarly when you start working with online inference and near-real-time datasets. You have to reason about the interplay between model complexity, data volume, and client application’s SLA. You need to ensure your datasets are available in online stores and consider query complexity, read-write latency, and transaction consistency. Most modeling and deployment layer tools are not well-designed to help us think about the interplay between data systems and model performance.
The final anti-pattern happens when all of the components in the ML stack are not explicitly or transparently connected. Even the best ML-driven applications are still brittle today because the dependencies between these components are so opaque. For that reason, many teams are reluctant to iterate on their ML-driven applications even when they know they are potentially leaving value on the table.
Sarah argued that there are a few things that the ML community, both builders and users of ML tools, can do better:
Collaborating with each other to define standards and best practices.
Considering how tools help implement these practices and clarify the specific problem the tools solve.
Developing “strong opinions, weakly held” about what components of the ML stack should be loosely or tightly coupled.
Pursuing integrations and partnerships.
Sarah concluded her talk with a few questions about the future of the ML stack, such as: What role will collaboration play in the future of ML? How will the adoption of pre-trained models impact the architecture of the ML stack? Will ML tools for structured data and unstructured data use cases converge or diverge? She emphasized that we need to stop thinking about MLOps as ModelOps and really focus on building a unified stack that will allow us to build reliable ML-driven applications.
5 — Is Production Reinforcement Learning at a tipping point?
Reinforcement Learning (RL) has historically not been as widely adopted in production as other learning approaches (particularly supervised learning), despite being capable of addressing a broader set of problems. But we are now seeing exponential growth in production RL applications, so much so that it looks like production RL is about to reach a tipping point to the mainstream.
Waleed Kadous (Head of Engineering at Anyscale) talked about why this is happening, detailed concrete examples of the areas where RL is adding value, and shared some practical tips on deploying RL in your organization.
The RL complexity spectrum includes the following stages:
Bandits: This is a fairly straightforward, well-understood technology. A practical example of bandits is UI treatments, where you treat each UI as a bandit and test how they perform to drive engagement. The key challenge is the explore-exploit tradeoff: how do you balance using your existing policy versus searching for a better policy?
Contextual Bandits: They are similar to bandits, but the variables that affect the performance may not be visible to you. A practical example of contextual bandits is recommendation systems, where the usual configuration is the user’s profile, and the state is the set of recommended items.
Reinforcement learning is essentially contextual bandits with states. A practical example of RL is playing chess, where there is a long chain of state connections within the games. A new problem that RL introduces is temporal credit assignment: if you have to go through a sequence of steps to get a payout, how do you work out how to distribute the reward over the last few moves? The state-space gets very large, and your reward might get delayed.
RL in large action and state spaces: In this scenario, the dimensionality and possibility grow (for instance, trading stocks in the S&P 500). Both your state-space and action-space grow exponentially.
Offline RL: What if you only had the logs of every lever pull and the reward for yesterday, and you just want to make the best policy from it? Offline RL answers the question: how do you build an RL model when you cannot run the experiments you want. A practical example of offline RL is learning from historical stock purchases. Like the other stages, you will deal with the temporal credit assignment, the curse of dimensionality, and the sensitivity to distributional shift.
Multi-Agent RL: What if there are multiple agents in the environment? How would you share information? Do you set up a competitive or cooperative situation between the agents? In multi-agent RL, things get very complicated. How do you define your reward function? How do you model different engines? Do they each have a different model?
Even though RL has been hugely successful in research (with applications like AlphaGo and AlphaStar) and adopted in big organizations, Waleed pointed out that four things make production RL hard:
High training requirements: For example, AlphaGo Zero played 5 million games against itself to become superhuman. Alpha Star agent is trained for 200 years. Training requirements like that go well beyond the capabilities of a single machine. Thankfully, recent progress in distributed training, transfer learning, bootstrapping from existing states, action masking, etc. has helped reduce this difficulty.
Overcoming online training limitations: RL’s naive default implementation is online. It is hard to validate models in real time and reuse data if model parameters are changed. The recent innovation in offline training algorithms can help deal with counterfactuals and overcome the limitations of online training.
Solving temporal credit assignment problem: Actions do not immediately lead to rewards in real life. This problem introduces a host of problems that significantly increases training data requirements. Though limited, contextual bandits do not have this problem, so they are simple to deploy and should be adopted more.
Large action and state spaces: Large action and state spaces require much more training, making them impractical for real-world problems. Recent progress in dealing with this scenario includes high-fidelity simulators, distributed RL libraries/techniques, deep learning approaches to learning the state space, embedding approaches for action space, and offline learning.
Waleed then outlined the three patterns he has seen in successful production RL applications:
Parallelizable simulation tasks: Since RL takes a lot of iteration to converge and is too slow for the real world, you can think about doing RL in simulated environments. You can run lots of simulations at once using a distributed RL library (such as RLLib), utilize systems for merging results from lots of experiments, and fine-tune simulated results in the real world.
Low temporality with immediate reward signals: Remind that RL is basically a combination of contextual bandits and sequentiality. Waleed argued that we could either ignore sequentiality or unroll sequentiality into the state. Specifically, on the latter point, you can use embeddings to reduce the complexity of state and action spaces.
Optimization: RL is essentially data-driven optimization. While traditional optimization is very much about modeling, RL does not require modeling. It just runs experiments. Obviously, this takes much more computation, but it is often “plug-and-play” with optimization.
Waleed concluded his talk with two practical tips:
There are simpler versions of RL (stateless, on-policy, small, discrete state and action spaces, single agent). Try them first.
The MLOps and deployment around RL are very different (in terms of validation, updating, monitoring for distributional shifts, and retraining). Make sure to understand them.
To learn more about deploying distributed Reinforcement Learning applications in production, be sure to check out RLib, the leading open-source distributed RL library.
Production Use Cases
6 — Empowering Small Businesses with the Power of Tech, Data, and Machine Learning
Data and machine learning shape Faire’s marketplace — and as a company that serves small business owners, our primary goal is to increase sales for both brands and retailers using our platform. Daniele Perito (Co-Founder and Chief Data Officer of Faire) discussed the machine learning and data-related lessons and challenges he has encountered over the last five years on Faire’s journey to empowering entrepreneurs to chase their dreams.
Faire is a wholesale marketplace founded in 2017 to help independent brands and retailers thrive. Its mission is to help connect independent retailers and brands using the power of technology, data, and ML. Over the past five years, Faire has become the largest online independent wholesale community in the world, connecting 450,000 retailers with 70,000 brands. They are now servicing independent retailers in nearly 20 countries around the world.
As a marketplace, Faire has several data challenges: both on the product side (search/discovery/ranking, fraud/risk, seller success, incentive optimization, etc.) and on the platform side (experimentation, analytics, and ML platforms). In his talk, Daniele went over the main projects his team worked on year by year and the learnings he has seen as Faire grew.
In the first year, Faire’s size was roughly 4 people at the beginning going to 12 people towards the end.
Daniele was the only data person who had to make several decisions: what online database to use, how to replace data in the warehouse, what data warehouse to choose, how to stand up an events recording framework to understand what customers were doing on the website, how to stand up a BI tool, and how to stand up a real-time feature store to detect fraud. These decisions were very sticky because it is not easy to migrate things over.
In the earliest days of Faire, they had to choose between MySQL and MongoDB for their online database. Even though MongoDB is fast to set up and get off the ground, they eventually settled with MySQL due to its ease of replication, schema enforcement, and consistency.
The key learnings here are:
Make a lot of far-reaching decisions important to the success of your data and ML organizations.
Have advisors, employees, or co-founders who have worked with these systems in depth.
In the second year, Faire went from roughly 12 people to 45 people, and the size of the data team went from 1 to 3.
The data team focused on improving their search system, started to pay attention to orchestration, and standardized their core tables and analytics.
For the choice of orchestration tools, they went with Kubeflow since it seemed the best choice for ML orchestration built on top of the Google Cloud Platform. A year or two later, they had to revert to Airflow due to expanding use cases.
The key learnings here are:
Establish a decision-making rubric for architectural decisions early on.
Start when your advisors, employees, or founders do not have direct experience and cannot provide crisp advice.
In the third year, Faire went from roughly 45 people to 150 people, and the size of the data team went from 3 to 6.
The data team started unifying their feature store, building data quality monitoring (so that model predictions would not drift), and deciding on a new experimentation platform.
At the time, Faire had a homegrown experimentation platform that was very basic and limited. As they started evaluating several options for a replacement, they realized that it took longer than expected to synchronize the state between their internal warehouse and the external experimentation platform(s). Ultimately, the effort failed for the lack of use, and they went back to using the homegrown solution, which by then had become a proper experimentation platform with all sorts of powerful features.
The key learnings here are:
Consider the cost of maintaining data consistency when using external data platforms.
Ensure that your data infrastructure decisions are tailored to the specific composition of your organization.
In the fourth year, Faire went from being roughly 150 people to 300 people, and the size of the data team went from 6 to 12.
The data team started working on a more sophisticated version of the search discovery algorithm, real-time ranking for low latency inference. They also migrated their data to Snowflake from Redshift and used Terraform heavily.
Even though Redshift had served them well for several years, the speed and scalability of Snowflake would be a big advantage for Faire’s use cases. Thus, they started embarking on the process of migrating thousands of tables/definitions/dashboards from Redshift to Snowflake. This painful process took them over six months.
The key learnings here are:
Ensure that you have a project tracker and good project management around big data infrastructure changes.
Define accuracy thresholds explicitly so people can finish the job during data migrations.
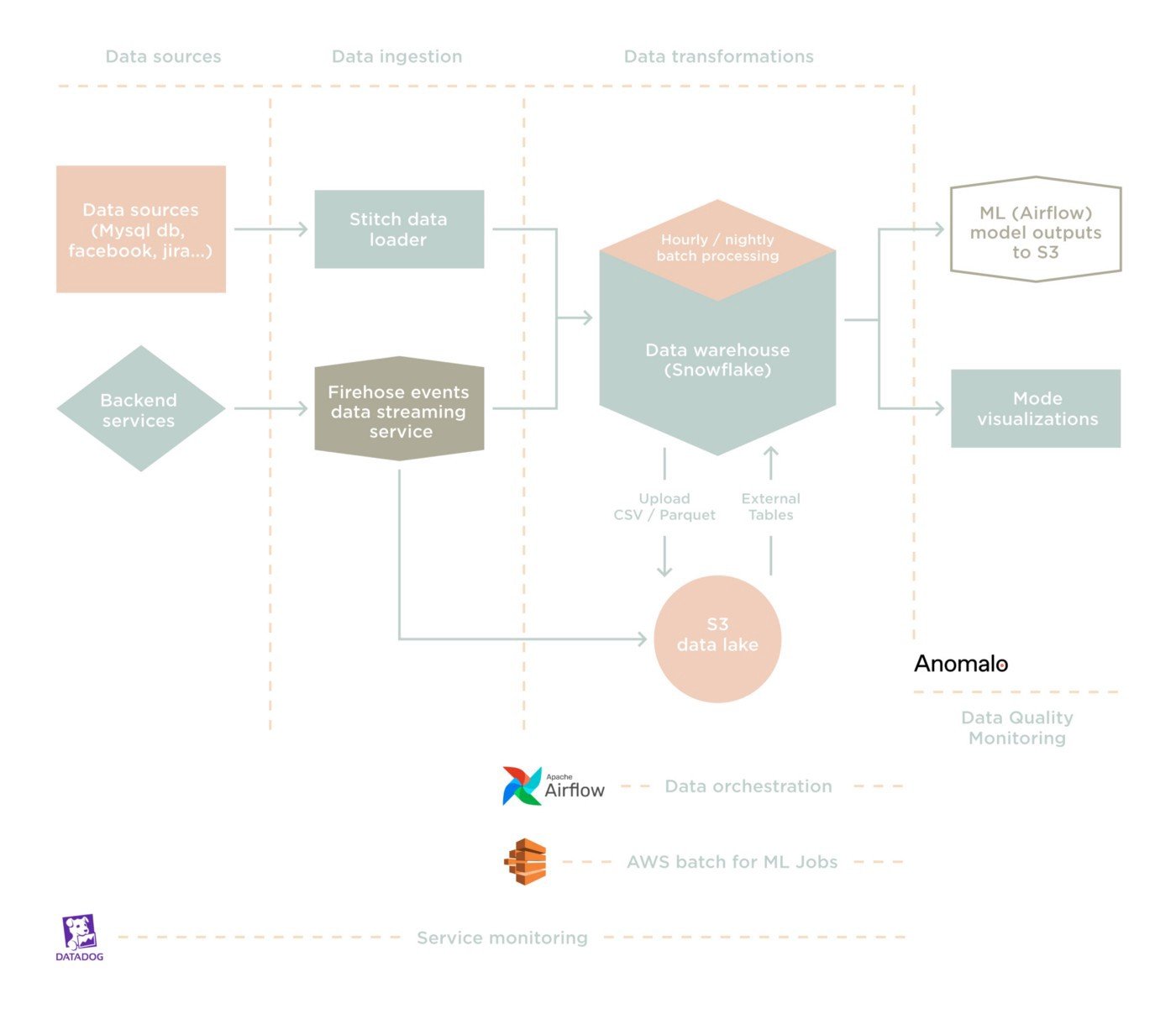
In the fifth year, Faire went from being roughly 300 people to 800 people, and the size of the data team went from 12 to 30.
The data team started the unification process for their ML platform (feature store, model training, model registry, model serving, model monitoring) and analytics platform (metrics, summary tables, fact tables).
The main learning here is to ensure that you have seasoned technical leaders or committees in your organization who can understand when it is time to invest heavily in the future.
Daniele concluded his talk with these takeaways:
Have people with data infrastructure experience in the early days of your journey.
Enforce close collaboration between engineering and data from the early days.
Establish rubrics about your data decisions as soon as you start scaling the team.
Consider the composition of the team when making data choices.
7 — Compass: Composable and Scalable Signals Engineering
Abnormal Security identifies and blocks advanced social engineering attacks in an ever-changing threat landscape, so rapid feature development is paramount for staying ahead of attackers. As they have scaled their machine learning system to serve thousands of features for hundreds of machine learning models, it has become a major focus to balance stability with rapid iteration speed.
Justin Young (software engineer at Abnormal Security) presented a framework called Compass developed at Abnormal. Compass models feature extraction pipelines as a DAG of composable functions. It enables machine learning engineers to express feature extraction logic in simple, pipeline-agnostic Python functions while also providing a way to interface with a feature store in a scalable way when needed.
Abnormal Security’s goal is to stop all email-based cyber attacks. As an ML problem, they have stringent requirements such as high recall, high precision, and rapid iteration cycles. Thus, the ML platform team has a mantra of “moving fast and do not break things” — it should be easy to add and remove signals, hard to break existing signals, and capable of running the pipelines both online and offline. There are two big challenges associated with this initiative: entanglement (what happens when a certain change to the system has a wide blast radius) and online/offline skew (what happens when the data or the logic being served online is different from what is being served offline).
Entanglement is a succinct way of saying that changing something at the beginning of the pipeline can cause the whole thing to break later. A solution to address this issue is function composition — rewriting a function in a composed form that achieves exactly the same. Within this function, we only care about the inputs and outputs. We want to iteratively transform our input data until we get some model prediction, regardless of what the intermediate functions are.
However, the function composition might be unconstrained because the data model is too flexible. There are dependencies between and across stages, leading to a tangled mess of dependencies. The more signals are extracted, the more dependencies are required. To avoid this issue, Justin brought up an insight saying that you only need a small number of inputs on average for every function. If you do that, your graph of dependencies will look more like the picture on the right below.
To make this work, you can explicitly model the inputs and outputs of every function. If you do that, you will not have to make the wide assumption that something at the top can change something at the bottom since you know precisely what the dependencies are in the graph. Since there are functions that transform inputs and return outputs, you can think about the whole thing as a graph of signals.
To execute this pipeline, they relied on a simple algorithm: First, topologically sort the graph of signals. Second, initialize the signal collection with an append-only data structure. Third, execute every transformation in order.
With a well-modeled DAG (Directed Acyclic Graph) of signals, they also got some nice utilities: they could (1) easily understand the pipeline by visualizing a graph or a listed dependency of signals, (2) validate properties about the pipelines such as the graph having no cycles, no used branches, and wasted computation, and (3) platform-ize common pipeline execution patterns by optionally propagating missing signals or error results downstream in the graph or doing parallel execution of parallel DAG paths.
The DAG above is composable and minimally entangled, but it is not necessarily scalable. They allowed users to optionally override online transformations with special offline logic. As a result, their pipeline will be the same online and offline, and any differences will be isolated to individual functions. The overall pipeline should be scalable.
Justin concluded the talk by making a distinction between a feature store and a function store. A feature store registers data sources, serves the data online/offline, and separates behavior online/offline. A function store does the same thing, but for the logic that is transforming your data. Both stores are equally important, so make sure your feature platform can do both.
8 — Why is Machine Learning Hard?
Tal Shaked (ML architect at Snowflake) worked at Google for nearly 17 years and did a lot of ML work, including research applications, ML-powered products, and the ML platform used throughout the organization. He shared his learnings over that time and gave his perspective on why he felt ML is hard to do well. More specifically, he broke this up into three chapters: ML for ranking in web search, large-scale logistic regression for ML ads, and ML platforms adapted to the rise of deep learning.
From 2004 to 2007, Tal worked on ML applications for Google search. At the time, Google had roughly 1,000 labeled queries. Each query had around 40 results out of 4 billion that were labeled as irrelevant or not relevant. Because this was a ranking problem, they looked at the relative ranking between different results, around 1 million examples in total.
The main takeaway he had from doing ML for ranking and web search is that data and quality problems are hard.
It was challenging to create good data — such as generating appropriate labels and metrics, computing and managing features, and continuously updating data with new features and labels as the world changed.
It was challenging to understand, debug, and improve quality problems — such as diagnosing and fixing predictions made by ML, integrating ML into the rest of the software and business logic, and discovering the objective to optimize along the way.
Additionally, Tal pointed out that it was hard to build very accurate models, but it did not matter much because they did not have the right objective. People were not comfortable handling the ranking function to ML at that time at Google.
Between 2007 and 2009, Tal focused on ML for ads. The reasoning was that everything was measurable (user clicks, value to advertisers, revenue to Google, etc.). That led to the development of a system called Sibyl, which focused on large-scale logistic regression to predict the clickthrough rate for ads. Sibyl was designed to train on 1 trillion examples with roughly 100 features and support about 5 billion parameters.
Initially, with Sibyl, it was easy to get a 10% improvement in offline metrics over three months. They built new algorithms and iterated on experiments offline in a controlled environment.
Then, as they managed to get the most high-performing model (in offline metrics) into production, it was surprisingly hard to get even a 1.5% improvement in live traffic. It turned out that ads were not as measurable as they thought, and all kinds of data and quality problems (due to complex business logic) arose. They had to re-implement the learning algorithm and change the underlying infrastructure.
Finally, they realized that there was a whole bunch of production work they had to do in order to integrate ML into production systems (training multiple models, running multiple experiments, monitoring these models, checking for outages, rolling them back when they underperform, etc.).
Sibyl became an end-to-end platform that powered the other ML initiatives at Google from 2009 to 2016, with use cases ranging from YouTube to Android. It was one of the most widely deployed systems at Google, with hundreds of models being trained at any given moment around 2015.
The main takeaway he had from building ML for ads and the rest of Google is that productionizing ML is hard.
ML is much more than models that get bolted onto software and products. It was difficult to seamlessly integrate ML into production software systems.
Almost every team struggled with data and quality problems. It was especially difficult to map offline metrics to online performance.
Sibyl’s learning algorithm was overkill for 90% of the use cases. It was all about how fast a developer could experiment with a model in production.
Ease of use for modeling and software development was the most important attribute. They leveraged standard compute frameworks (MapReduce, Flume, and Borg) and supported integration with multiple data formats, serving systems, and experiment frameworks.
Since 2016, teams inside Google have started using deep learning algorithms more frequently. However, they ended up spending roughly one to two years trying to productionize it. Essentially, they were rebuilding the same production pipelines but for deep learning. To address this issue, Google created TensorFlow Extended, which replaced Sibyl and accelerated the adoption of deep learning across Google.
TensorFlow Extended was much more modular than Sibyl:
At the bottom layer lies common building blocks such as Borg, Flume, Google File System, and so forth. They constantly improved these systems, so they were designed to run the ML workloads in complex data pipelines.
In the middle layer resides all of the TensorFlow Extended components (logging, analytics, serving, training, etc.) On top of that, they built even easier systems customized to certain teams.
Having multiple layers, from basic building blocks all the way up to easy-to-use services, was useful, as people could pick and choose which pieces they wanted.
The main takeaway he had from building a platform for deep learning use cases is that ML engineering, as a discipline, is a superset of software engineering. When you build production systems, you need to bring in the best software engineering practices. You also have to deal with the peculiarities of complex processes involving code and data. Therefore, no single ML platform works well for all cases.
9 — Accelerating Model Deployment Velocity
All ML teams need to be able to translate offline gains to online performance. Deploying ML models to production is hard. Making sure that those models stay fresh and performant can be even harder. Emmanuel Ameisen (Staff ML engineer at Stripe) covered the value of regularly redeploying models and the failure modes of not doing so. He also discussed approaches to make ML deployment easier, faster and safer, which allowed his team to spend more time improving models and less time shipping them.
What is the value of regularly deploying ML models? Emmanuel argued that there are three big reasons:
Model drift: For many use cases in which you continuously learn from the world, such as fraud prevention at Stripe (as people who commit fraud always look for new ways to commit fraud), any model you train today will be obsolete tomorrow. The question is only by how much it will be obsolete.
Domain shift: Even if it is now a slow drift of the world shifting under your feet, your companies and users change regularly in subtle ways (for instance, if you launch in a whole new country). These changes can cause your models to slowly become out-of-date and eventually trained on a completely different distribution from what your inference is today.
Addressing the bottleneck: ML gains only count once they are shipped. Deploying models should be something you can do safely. If a model is important, you should be able to fix it quickly if it breaks.
The picture above shows Emmanuel’s mental model on the skills needed to deploy models regularly:
To get a good model, you need 90% data generation/cleaning and 10% modeling.
If you want to ship this model, only 10% of the work is getting the good model. The other 90% relies on software engineering best practices.
If you want to serve and update that shipped model reliably, most of the work falls on operational excellence in running your training jobs, evaluation plans, and deployment pipeline.
Producing a model is complicated and cyclical: you generate the data, filter the data, generate your features, generate your training and evaluation sets, train your model, and evaluate the model on the test set for business metrics. Then you deploy the model, monitor the model, and evaluate the model performance in a production environment that will feed into the data used to train your model.
Reliably training models require you to reliably do all of these tasks regularly. Emmanuel recommended automating most of these tasks. In other words, you want to have each of these tasks be a job that can be automated without a single human in the loop. In Stripe’s case, they keep a human in the loop in two stages — deployment and production performance evaluation.
The other trick to de-risk this automated pipeline is to leverage shadow mode. Shadow mode means you basically deploy not just your production model to your production environment, but also shadow models. These shadow models make predictions just like the production model. You can store the shadow predictions for later to test models at the end of the pipeline.
If you want to learn more about how Stripe does ML releases, check out Stripe Radar technical guide with more in-depth information.
10 — Streaming NLP model creation and inference
Primer delivers applications with cutting-edge NLP models to surface actionable information from vast stores of unstructured text. The size of these models and their applications’ latency requirements create an operational challenge of deploying a model as a service. Furthermore, creation/customization of these models for their customers is difficult as model training requires the procurement, setup, and use of specialized hardware and software.
Primer’s ML Platform team solved both of these problems, model training and serving, by creating Kubernetes operators. Phillip North and Cary Goltermann (ML Engineers at Primer) discussed why they chose the Kubernetes operator pattern to solve these problems and how the operators are designed.
One of Primer’s first products is Analyze — a news summarization, aggregation, and exploration tool that helps analysts collect information about anything that could be happening in the news worldwide so they can make better decisions. Another product is Command, which provides visibility on real-time streams of social media and classified data (i.e. intelligence use cases). Lastly, Primer’s customers who use these products want to add a custom type of entity extraction to the type of information they pull out of news, or they may have a bespoke type of use case for their workflow and need an NLP solution for it.
As an NLP company, Primer faces a whole suite of problems.
For their products that are mostly ingesting streaming data, they need a solution that hits various requirements of being fast, reliable, cost-effective, handling bursts, and supporting any model type. There’s no simple way to solve all of these requirements without some degree of complexity.
For training custom models, they need to train large NLP models on big datasets across distributed hardware. There’s a lot of complexity that goes along with provisioning the resources, doing parallel cross-validation and large-scale evaluation, and integrating with the serving solution.
They approached these problems by creating declarative APIs for NLP infrastructure in order to make it easy for data scientists to get and manage the type of hardware that they need to run their models. They accomplished this with Kubernetes Custom Resources by extending Kubernetes to allow their NLP infrastructure to be served on top of Kubernetes.
The declarative API for model serving looks like the picture above:
Instead of having to enumerate all the things that you want and how your endpoint should be provisioned, they expose a high-level API that lets the author simply state what they want. More specifically, the model author only needs to come with an implementation of their model as a class.
For heavy users training models, they create an autoML declarative solution. The user just needs to specify the data and make sure that it conforms to a schema expected for the specific model type.
Being declarative lets them run models in any generic environment, allows them to have a static view of all the assets getting deployed, and lets data scientists trust the deployment process to focus on the quality of their model implementation.
In short, declarative APIs allow users of Primer’s ML Platform to care about what they want to do, not how it is implemented. This allows them to get more models to get into production faster and serve them in many environments.
Open Source
11 — Declarative ML Systems: Ludwig and Predibase
Declarative Machine Learning Systems are a new trend that marries the flexibility of DIY machine learning infrastructure and the simplicity of AutoML solutions. Piero Molino and Travis Addair (CEO and CTO of Predibase, respectively) presented Ludwig, the open-source declarative deep learning framework, and Predibase, an enterprise-grade solution based on it.
There is a false dichotomy in the ML space today. On the one hand, there is a DIY approach with low-level APIs, and on the other hand, there is AutoML that automates the ML development process. But both solutions do not solve the underlying problem — the efficiency of the ML development process. Reflecting on his experience at Uber working on a number of ML projects such as intent classification, fraud detection, and product recommendation, Piero recognized that ML projects have too long time-to-value, bespoke solutions lead to high technical debt and low reproducibility, and most organizations cannot hire enough ML experts.
With a declarative ML system, you get both the flexibility of a low-level API DIY approach with the simplicity of an AutoML solution in the same place since you have a higher abstraction providing flexibility, automation, and ease of use. Non-experts now can be empowered to use ML. These concepts have been pioneered since 2017 with the open-source projects Overton and Ludwig.
Ludwig is an open-source declarative deep learning approach.
The idea behind it is that you can use a decorative configuration system instead of writing your own code for doing your ML projects. This makes development much faster, more readable, and more reproducible.
At the same time, Ludwig keeps the flexibility of expert-level control. You can change all the details of your model and pipeline by changing parts of the configuration system. This makes it easy to iterate and improve the models. It is also extensible because you can add your own pieces of code that are referenced throughout the configuration system.
Finally, it contains advanced capabilities like hyper-parameter optimization, state-of-the-art models, and distributed training.
The basic architecture of Ludwig is this encoder-combiner-decoder architecture, as seen above. The input part has many different data types that can represent the columns of your data. They are preprocessed and then coded to a common vector representation, which is combined by the combiner. Then you have a decoder that predicts, depending on the data type of the data that you are training on, the output of the model. This end-to-end deep learning architecture is really flexible and can be instantiated for different tasks.
The Ludwig team has done a lot of work in the past year to develop a scalable backend built on top of Ray. This allows you to scale up arbitrarily large datasets and perform distributed data pre-processing using Dask, do data-parallel distributed training of the model using Horovod, and orchestrate the whole thing end-to-end using Ray. Furthermore, this abstraction does not require you to provision sophisticated heavyweight infrastructure. Since everything runs in a common layer, the same code that executes normally on your laptop can be made to run in a distributed manner.
Piero and Travis recently founded Predibase to bring declarative ML to the enterprise. They take care of not just individual user’s model development problems but also the end-to-end problem of how enterprises think about data flowing through ML models and getting into production to drive value. That consists of primarily three distinct parts: connecting data from a database or a data lake, using declarative model training with a Ludwig-like interface, and deploying that model for both batch and real-time prediction using various interfaces from REST to SQL-like.
Predibase is a low-code ML platform that provides high performance and high flexibility:
Thanks to the declarative system that’s tightly bound between the model and the data schema, Predibase has a layer on top of the models that come out of Ludwig called PQL, a predictive query language that allows you to make scalable batch predictions. This brings ML to the data and puts this capability into the hands of people who would traditionally not interact with ML systems.
Predibase uses the same powerful and flexible configuration system that people in the Ludwig open-source community are familiar with, but with extra features on top.
Predibase also provides state-of-the-art ML infrastructure without the need to build an entire advanced ML infrastructure team. This serverless layer is built on top of the Ludwig-on-Ray open-source product that completely removes the complexity of operationalizing and productionizing ML.
The workflow with Predibase looks like the diagram above:
First, you take your structured or unstructured data, which can be in a data lake or a data warehouse, and connect it to any dataset table-like structure.
Predibase will allow you to build the models using a declarative interface.
Then you operationalize those models using PQL for batch prediction and supporting full REST deployments for real-time prediction.
Things circle back as you can iterate on the models over time and evolve them when data drifts and model performance degrades.
Overall, the platform provides an observability layer that gives you the end-to-end MLOps experience.
12 — The dbt Semantic Layer
Drew Banin (Co-Founder of dbt Labs) discussed the dbt Semantic Layer and explored some ways that Semantic Layers and Feature Stores can be leveraged together to power consistent and precise analytics and machine learning applications.
People in the BI and analytics sphere are talking about “semantic layers.” The big idea at play is that you want to (1) define your datasets and metrics, (2) map out how they relate to each other, and (3) translate “semantic” queries into SQL for execution. Some examples of metrics that you might want to define once and use everywhere are revenue by country, average revenue per customer, weekly active users, or churn rate. Managing these metrics deserves new technology innovations since they should be precisely defined and change infrequently.
The diagram above shows a DAG generated by dbt:
The pink node is a metric. It is the actual aggregation that misses a lot of the logic needed to calculate this metric correctly.
All the blue nodes are the logic applied to source data to join datasets together from different sources (aggregations, filtering, etc.).
This whole chain of logic, plus the actual metric definition, composes the final metric.
Drew argued that semantic layers and feature stores sound like similar concepts. If you have many people on different teams accessing the same features or metrics, you want to ensure that the features and metrics are consistent. The work should not be repeated, or else inconsistencies arise and you get invalid/incorrect data.
The thing that links together the semantic layer concept in BI and analytics with feature stores in ML engineering is standardization. Whether you create inputs for ML training and serving or outputs for analytics and data science, you want to make sure that when you invest the energy to define these constructs, features, metrics, etc., you do it correctly and have a good way of evolving this logic over time as requirements and the product experience invariably change. In other words, features in ML are akin to dimensions/metrics in BI.
The diagram above displays Drew’s view of how to bridge the two worlds:
The data warehouse is front and center (it could also be a data lakehouse).
You have the transformation and business logic to apply to your data in order to make sense of it. From that point, you have this shared logic to either (1) make dashboards and reports that business users consume and understand or (2) power features to be used for ML.
With this shared parent between BI and ML use cases, you get both consistency and reuse. Investments that your BI or analytics team has made to model revenue or product usage activity could be leveraged for feature engineering in ML (or vice versa).
Unifying ML with analytics and BI helps people become more collaborative and create more precision/consistency for our work. Since they have different audiences for different use cases, semantic layers and feature stores are unlikely to collide. In contrast, the two worlds can learn from each other:
The analytics engineering community has learned a lot about how to collaborate around creating shared dimensions/metrics and how to work the business to make sure we understand these definitions precisely.
The ML engineering community has the expertise to define things once and use them in many places, leveraging the engineering background.
13 — Wild Wild Tests: Monitoring RecSys in the Wild
As with most Machine Learning systems, recommender systems (RecSys) are typically evaluated through performance metrics computed over held-out data points. However, real-world behavior is undoubtedly nuanced, and case-specific tests must be employed to ensure the desired quality. Jacobo Tagliabue (Director of AI at Coveo) introduced RecList, a behavioral-based testing methodology and open-source package for RecSys, designed to scale up testing through sensible defaults, extensible abstractions, and wrappers for popular datasets.
Evaluating RecSys with the standard metrics that we use (both in research and industry) is not enough. This is an issue because evaluating them is crucial to their actual effectiveness in the real world. The problem with RecSys (as in many ML systems) is that when they fail, they fail silently. Additionally, the feedback that RecSys typically gather in the real world may not tell how the RecSys are producing a good user experience for the final user.
Do our current tests capture these issues? A way to solve this problem is behavioral testing — we do not evaluate with one single quantitative metric but instead enforce some input-output pair that we deem important in the use case at hand. Here are three behavioral principles at play:
Look for inherent properties of use cases: Similar items are symmetric, while complimentary items are asymmetric.
Measure how bad a mistake is: If we take a purely quantitative metric like hit-or-miss or hit-rate, we do not get a sense of how far we are from the actual truth.
Not all data points are created equally: You can get a good aggregate metric just by optimizing the most frequent items. But you also need to look for items on the long tail.
To solve this problem at scale, Jacobo and colleagues introduced RecList, a package for behavioral tests and RecSys. It is open-source, peer-reviewed, and is built by the community for the community.
RecList is based on the collaborative abstraction similar to Metaflow. You create a class unit, a RecList class, and then any Python function (as long as it is properly decorated to create behavioral tests). A huge point of RecList is that it comes pre-made with many behavioral tests that you can use on many public datasets.
RecList can be used for research if you are running a new model and see how it is performing, not just based on pure quantitative metrics but also behavioral ones. You can use it in production systems — for example, in your CI/CD, before promoting a model to deployment, you may want to test not just its accuracy but also the behavioral principles mentioned above.
Be sure to check out RecList on GitHub and spread the good news about using behavioral testing for recommendation systems!
14 — ralf: Real-time, accuracy-aware feature store maintenance
Feature stores are becoming ubiquitous in real-time model serving systems. However, there has been limited work in understanding how features should be maintained over changing data. Sarah Wooders (a Ph.D. student at UC Berkeley) presented ongoing research at the RISELab on streaming feature maintenance that optimizes both resource costs and downstream model accuracy and introduced a notion of feature store regret to evaluate feature quality of different maintenance policies and test various policies on real-world time-series data.
In any kind of feature store system, we have incoming datasets that we transform with feature transformations. Then, we store those features in offline and online stores, which we then train to serve to model training and model serving systems. Sarah’s talk focuses on the feature transformation step — where we transform raw data into features, keep features fresh as data changes, and reflect those changes in the feature stores.
Two major questions need to be answered in this step:
When should we process the incoming data? People often compute features with different frequencies. You might have very infrequent updates (i.e., once every 24 hours) or a streaming system (you recompute a feature for every single new event). There is a trade-off curve here: With infrequent updates, you have lower cost but more feature staleness. With more frequent updates, you have higher costs but better feature freshness. It is unclear where exactly you should land on this trade-off curve for different applications.
Which features should be updated? A lot of features can be de-prioritized and are not important for application metrics. For example, many features in a feature table might never be queried since you often see a power-law distribution with hotkeys getting queried and other keys never getting queried. Additionally, many features are changing slowly or do not have meaningful changes. Even if they become stale, it is not that big of a deal. If the staleness of the feature does not affect the model’s prediction quality, then it is not important to update these features.
In order to optimize feature maintenance, we want to consider the cost and the quality of the queried feature. We have a tradeoff curve between cost and quality, where the more compute resources we have, the higher quality we can make our features. Sarah’s research agenda focuses on improving this tradeoff curve by being smarter about what features to update.
Sarah defined feature quality in terms of how much worse models perform with ideal features and actual features. The ideal feature is calculated with an infinite compute budget, such as the perfectly fresh feature with every single data point incorporated with zero latency. The actual feature is the one you can affordably maintain, such as the feature you end up getting after running some hourly batch process.
With this notion of feature quality, Sarah defined feature store regret — which is the prediction error with the actual features minus the prediction error with the ideal features. Basically, the worse your featurization is, the larger this regret to be (since you lose out on model accuracy by having low-quality features). If you are able to measure the accuracy of your model, then you can approximate your feature store regret as features become more stale.
Her team designed a scheduling policy:
For a model serving system, you track the error for predictions made with different features to calculate some kind of error feedback.
You pass that feedback back to the feature maintenance system.
For every single key-value pair in a feature table, you track the cumulative regrets since the feature was last updated.
Then, you take the keys with the highest cumulative regret, update them, and set that accumulative regret back to 0.
Experiments show that they could achieve higher accuracy for the same cost by doing this regret-optimized scheduling. Furthermore, they found that freshness and accuracy do not always correlate perfectly.
Sarah’s team has implemented these scheduling ideas in ralf — a framework for feature maintenance. It has a declarative DataFrame API for defining features in Python code and allows for fine-grained control over managing feature updates. You can implement different ways of prioritizing which features you want to be updated over others. It is also specifically tailored for ML feature operations, written natively in Python and Ray.
Her team is looking for collaborators and new workloads, so if you think this might be relevant, reach out to contribute!
A huge thanks to Tecton for organizing the conference, alongside the sponsoring startup vendors and communities. If you are a practitioner, investor, or operator excited about best practices for development patterns, tooling, and emerging architectures to successfully build and manage production ML applications, please reach out to trade notes and tell me more!